芯耀辉软硬结合的智能DDR PHY训练技术


引言
DDR接口速率越来越高,每一代产品都在挑战工艺的极限,对DDR PHY的训练要求也越来越严格。本文从新锐IP企业芯耀辉的角度,谈谈DDR PHY训练所面临的挑战,介绍芯耀辉DDR PHY训练的主要过程和优势,解释了芯耀辉如何解决DDR PHY训练中的问题。
DDR PHY训练简介
高可靠性是系统级芯片SoC重要的质量和性能要求之一。SoC的复杂在于各个IP模块都对其产生至关重要的影响。从芯耀辉长期服务客户的经验来看,在客户的SoC设计中,访问DDR SDRAM是常见的需求,所以DDR PHY则成为了一个非常关键的IP,其能否稳定可靠的工作决定了整个SoC芯片的质量和可靠性。
制定DDR协议的固态技术协会(JEDEC)标准组织并没有在规范中要求动态随机存取存储器(DRAM)需要具备调整输入输出信号延时的能力,于是通常DDR PHY就承担起了输入和输出两个方向的延时调整工作,这个调整的过程称为训练(training)。训练是为了使DDR PHY输出信号能符合固态技术协会标准的要求,DDR PHY通过调节发送端的延迟线(delay line),让DRAM颗粒能在接收端顺利地采样到控制信号和数据信号;相对应的,在DDR PHY端,通过调整内部接收端的延迟线,让DDR PHY能顺利地采样到DRAM颗粒的输出信号。从而在读写两个方向,DDR接口都能稳定可靠地工作。
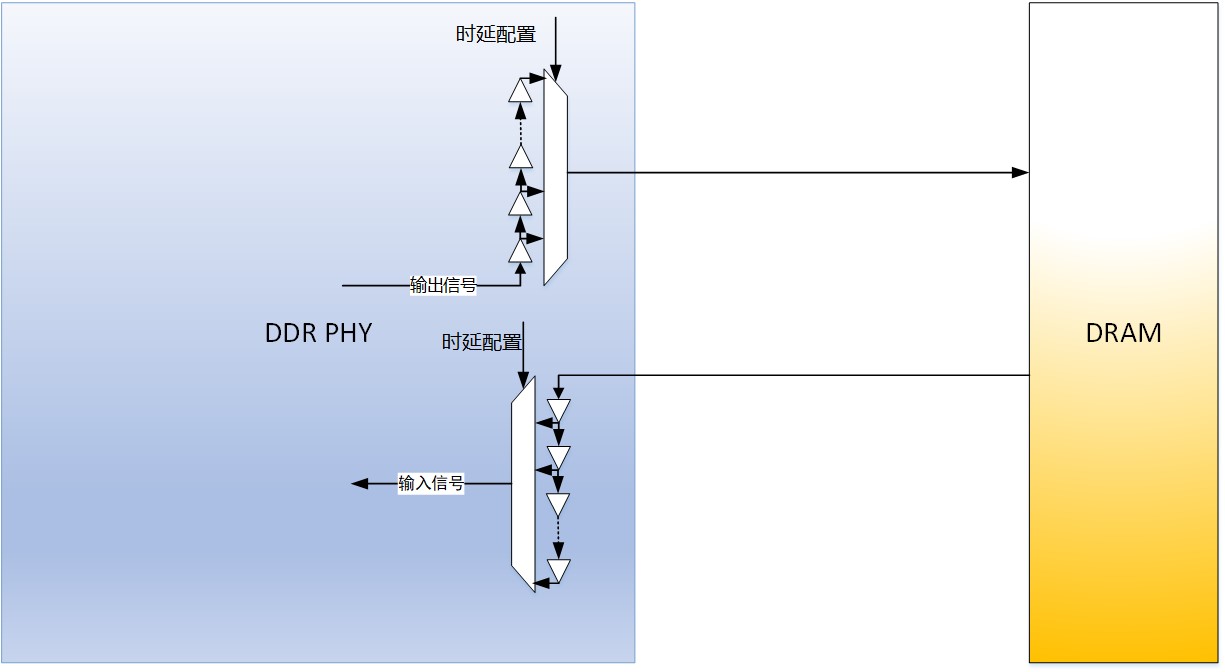
图1:DDR PHY承担了输入和输出两个方向的延时调整工作
然而,随着DDR工作频率提高,DDR PHY训练的准确性和精度要求也随之提高。训练的准确性和精度决定了DDR系统能否稳定可靠地工作在较高的频率。
DDR PHY训练所面临的挑战
DDR训练的种类繁多,每个训练的结果都不能出错。同时固态技术协会定义的训练序列都比较单一,如果只使用这些默认序列的话,训练结果在实际工作中并不是一个最优值。
目前绝大多数DDR PHY都采用硬件训练的方式,如果硬件算法有问题,会导致训练出错,DDR无法正常稳定地工作,导致整个SoC的失败。同时,硬件训练模式很难支持复杂的训练序列和训练算法,从而无法得到训练结果的最优解。
芯耀辉的DDR PHY采用软硬件结合的固件(firmware)训练方式跳出了上述DDR PHY训练模式的固定思维。
芯耀辉DDR PHY在训练上的优势
解决写入均衡(write leveling)的难题
写入均衡是为了计算出flyby结构下命令通路和数据通路的走线延迟的差值,在DDR PHY中把这个差值补偿到数据通路上,从而最终让数据通路和命令通路的延迟达到一致。
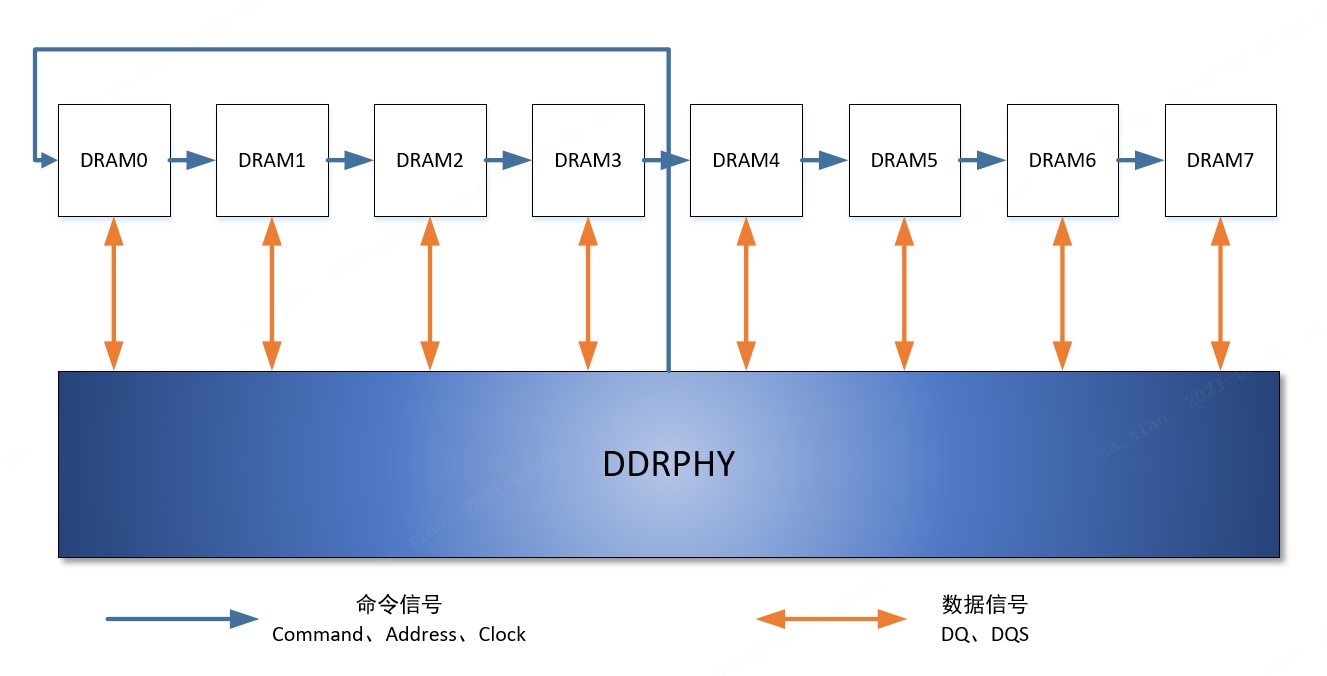
图2:DDR flyby拓扑结构示意图
在实际的应用中,命令(command)路径上的延时会超过数据(DQ)路径的延时。假设路径差值 = 命令路径延时 – 数据路径延时,一般路径差值在0~5个时钟周期之间。可以把路径差值分为整数部分和小数部分(单位是0.5个时钟周期)。
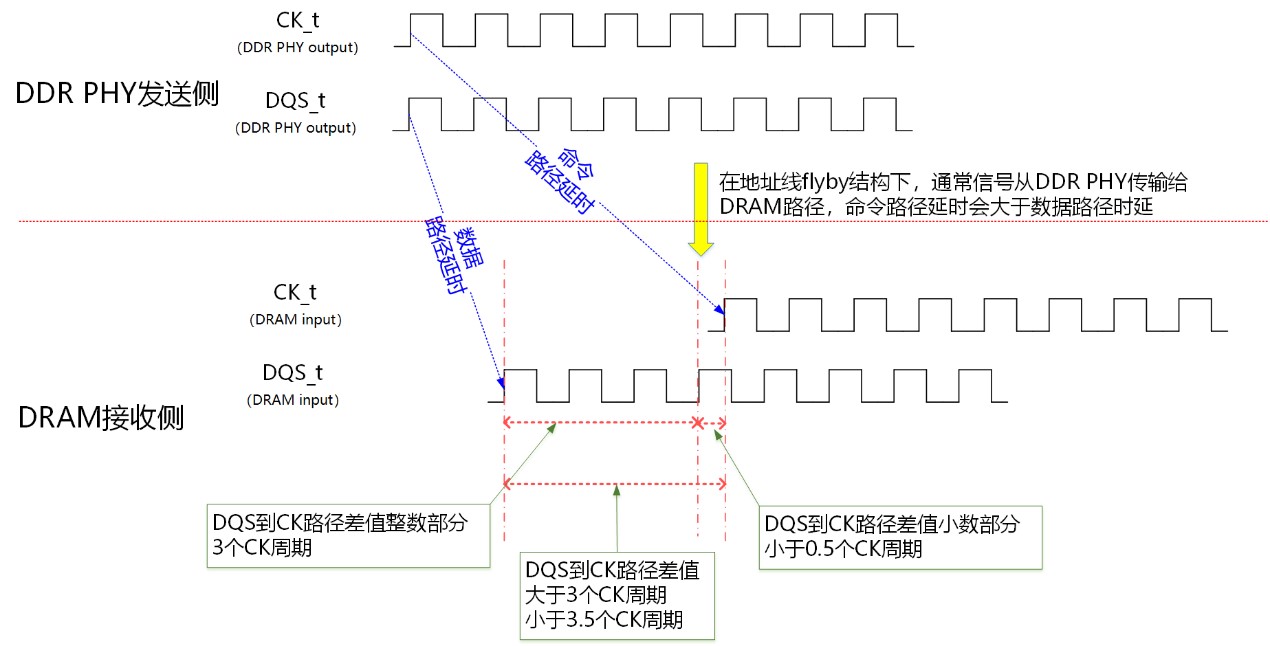
图3:命令路径延时、数据路径延时和路径差值
根据固态技术协会标准(如JESD79-4C)的写入均衡的要求,DRAM在写入均衡模式下会用DDR PHY发送过来的DQS沿去采样CK,并把采样的值通过DQ返回给DDR PHY。
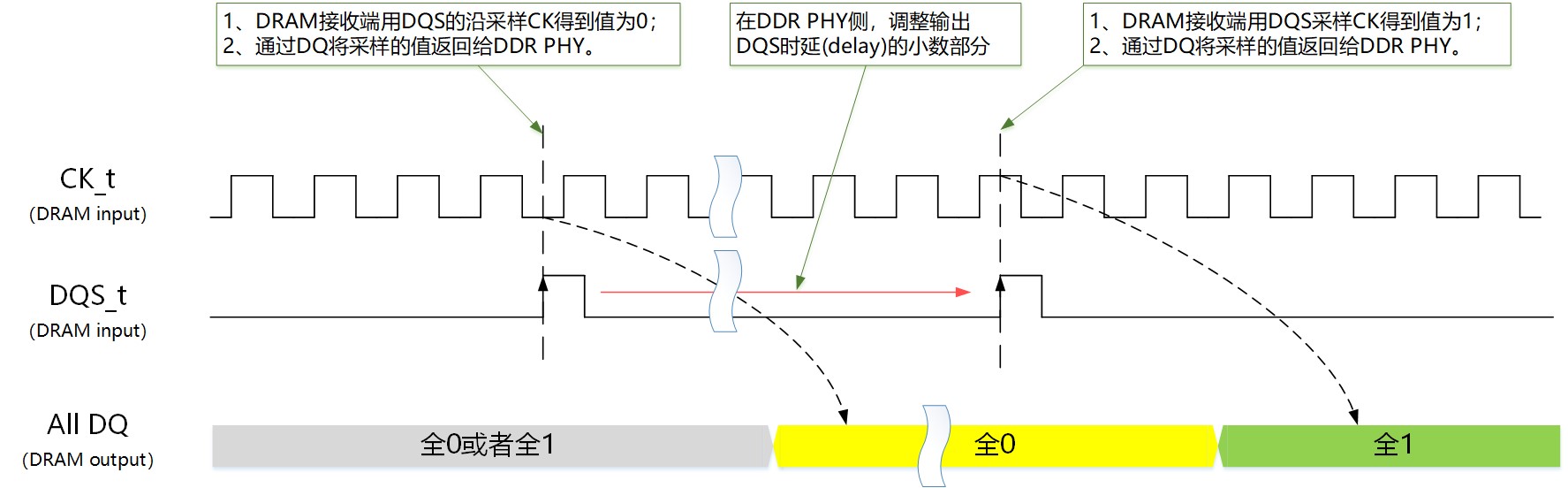
图4:写入均衡模式下调整DQS时延的示意图
通过该训练,DDR PHY可以计算出命令与数据路径延时差值的小数部分,却没有办法训练出命令与数据路径延时差值的整数部分(把DQS多延迟一个时钟周期或者少延迟一个时钟周期,用DQS采样CK的采样值是相同的)。
为了解决这个问题,通常会根据版图设计估算出大概的路径差值,从而自行得到路径差值的整数部分,直接配置到DDR PHY的寄存器中。这种做法在频率比较低、量产一致性比较好的时候问题不大。但在大规模量产的时候,如果平台之间的不一致性超过一个时钟周期(LPDDR4最高频下周期为468ps)的话,上述直接配置整数部分的方法就没法进行工作了,必然会导致部分芯片无法正常工作。
芯耀辉采用固件的训练方式,通过DDR写操作时特殊调节方法,能够帮助客户计算出路径差值整数加小数部分,无需客户根据版图设计估算路径差值范围。
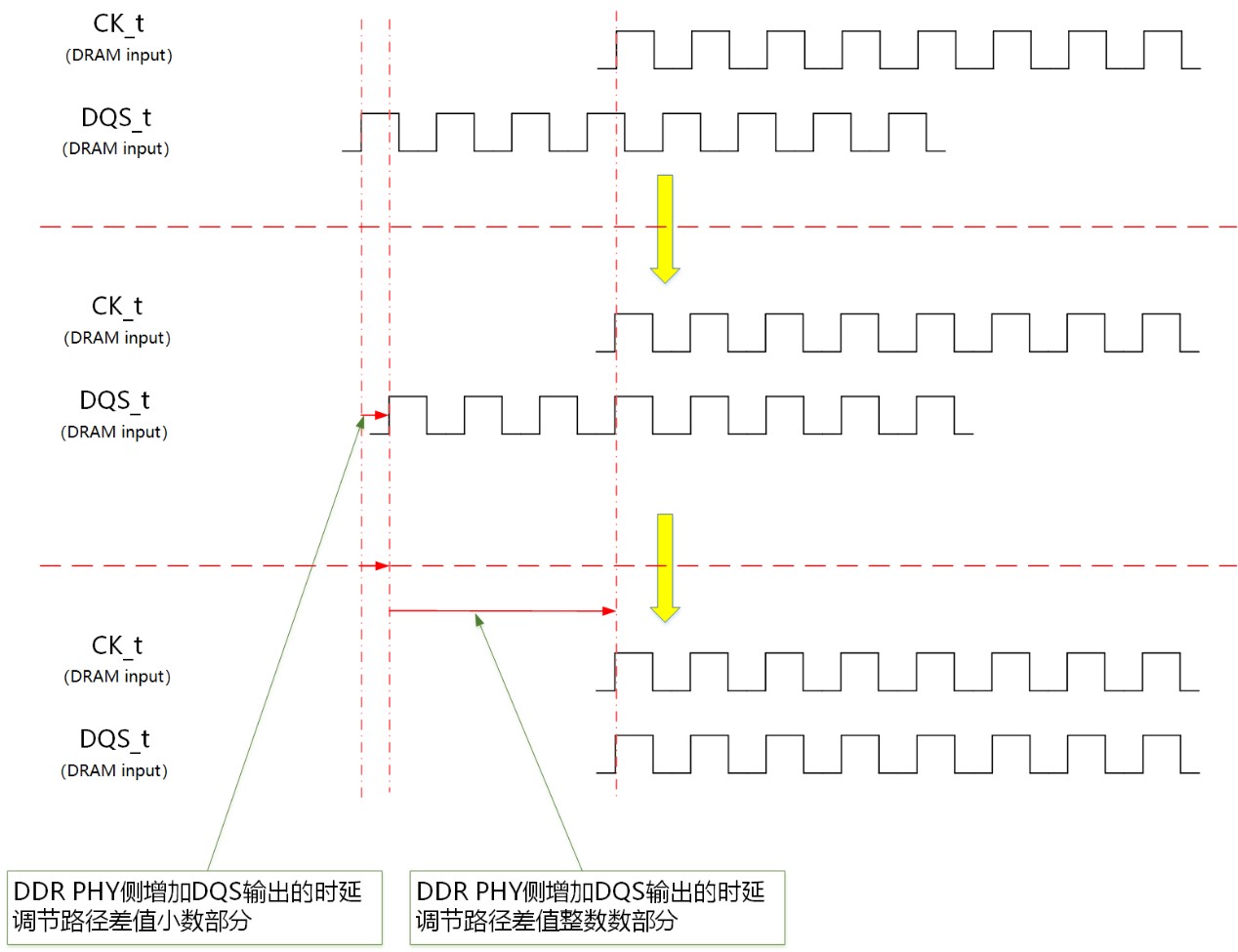
图5:路径差值整数部分训练和小数部分训练
过滤训练时DQS的高阻态
读操作时,DQS信号在前导(preamble)前是高阻态,同时DQS信号的前导部分也不能达到最稳定的状态,所以需要训练出读DQS的gate信号来过滤掉前面的高阻态和前导,恰好得到整个读突发(Read Burst)操作的有效DQS,这就是读DQS gate训练。
芯耀辉采用特定的方法,在训练的时候,排除不稳定DQS的干扰,用读DQS的gate信号得到读突发数据对应的第一个DQS的上升沿位置,从而得到gate的位置。
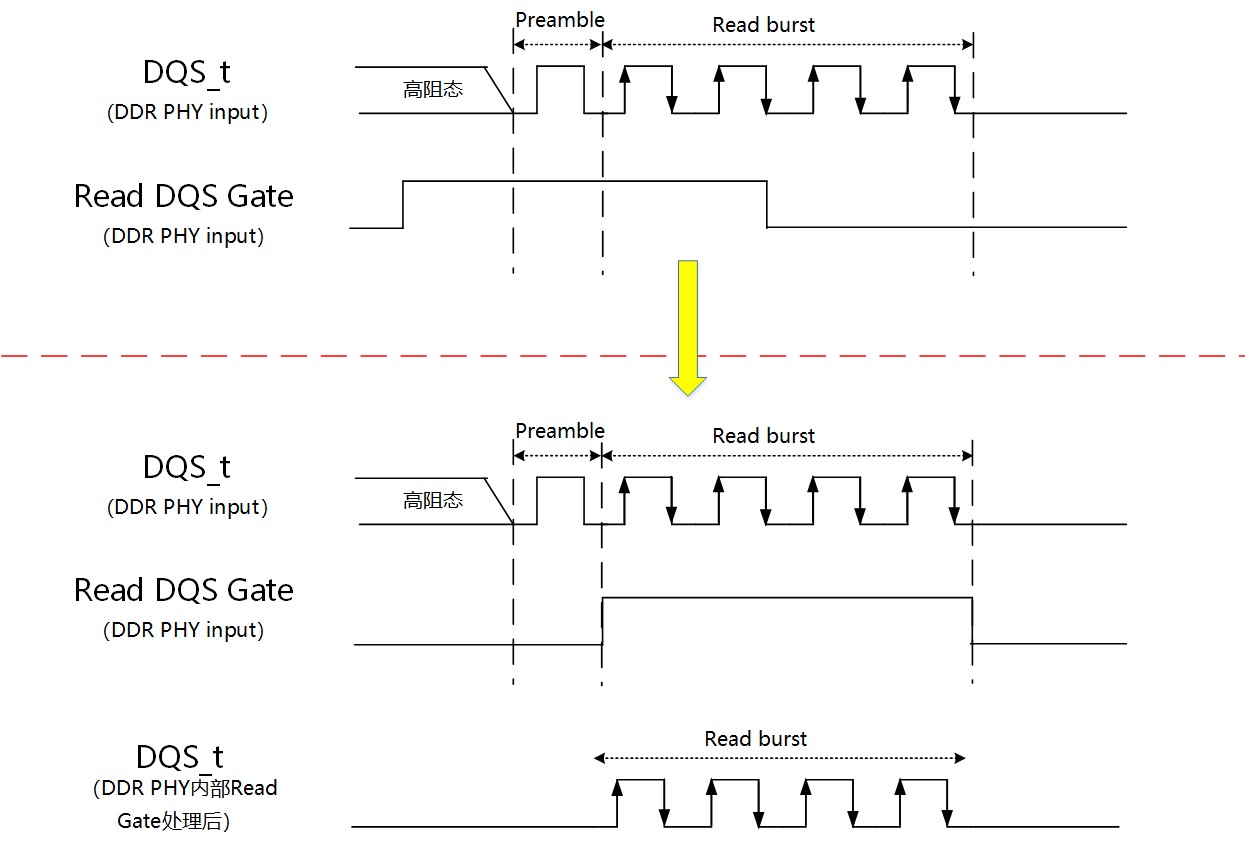
图6:读DQS gate训练
延迟DQS提高读DQ训练的准确性
一般在DDR PHY中没有这个训练,因为该训练不是固态技术协会标准要求的,可是在实际应用中,这个训练却有着比较重要的意义。
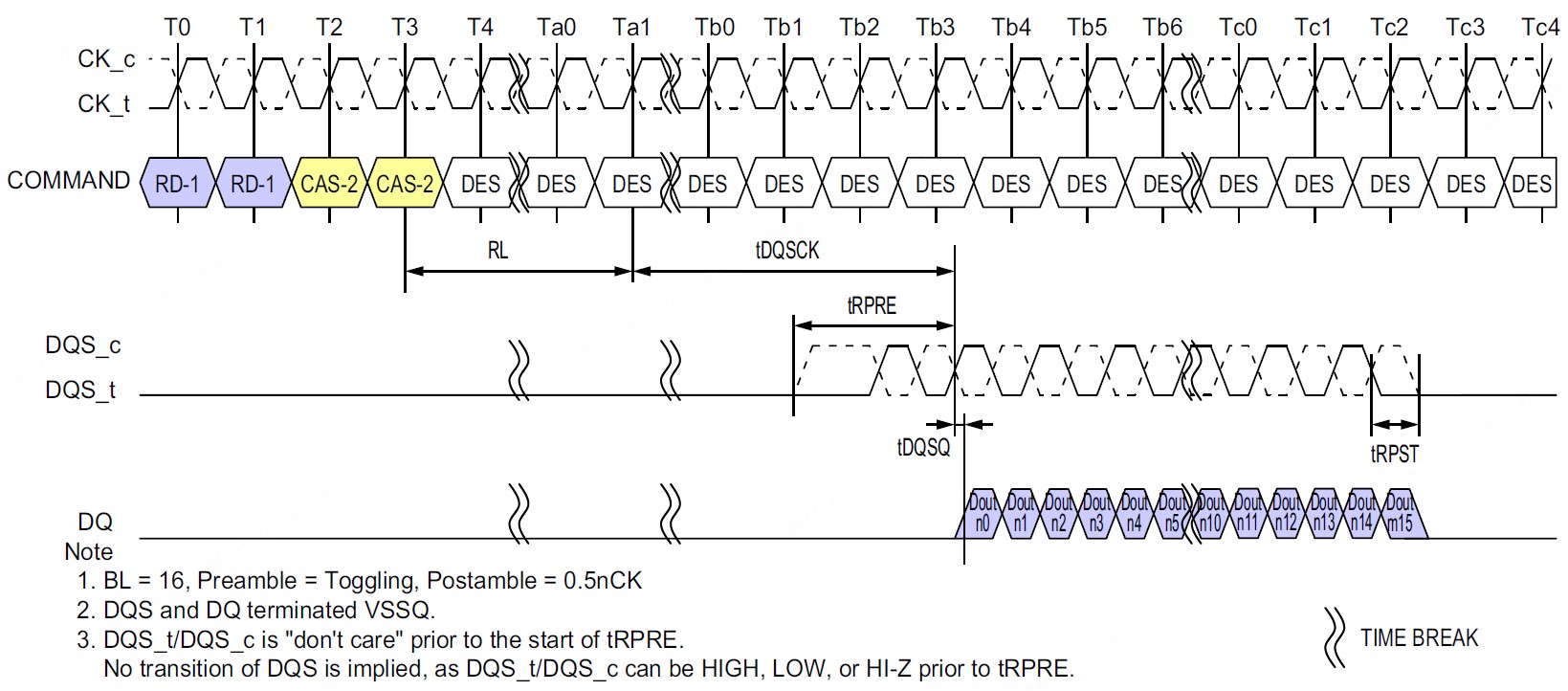
图7:LPDDR4突发读(来源固态技术协会标准JESD209-4B)
读DQS和读DQ之间的偏差为tDQSQ,这个值的范围是0~0.18UI(在高频下约为0~42ps)。读训练的时候,采用延迟DQS的方法,找到DQ的左右窗口,最后把DQS放在DQ窗口的中心点。由于DDR PHY内部的DQS-DQ延迟偏差、封装的pad延迟偏差、以及PCB走线偏差,虽然DRAM端输出的tDQSQ为正数(DQ的延迟比DQS大),但在DDR PHY内部看到的tDQSQ却可能为负数(DDR PHY内部DQS的延迟比DQ大),如图8上半部分所示。
在这种情况下,即使DQS的延迟为0,DQS也落在DQ的窗口内,PHY内部会通过从0延迟开始增加DQS的延迟来搜索DQ的左右窗口,这样必然导致最终搜索到的DQ的窗口比实际的窗口要小,读训练后的DQS的采样点不在DQ的正中间,而在偏右的位置,最终读余量(margin)变小。
芯耀辉通过特定的方法,能让每个DQ的窗口都在DQS右边,这样做读训练的时候,可以搜索到DQ的完整窗口,提高了读训练的准确性,提升DDR的读性能。
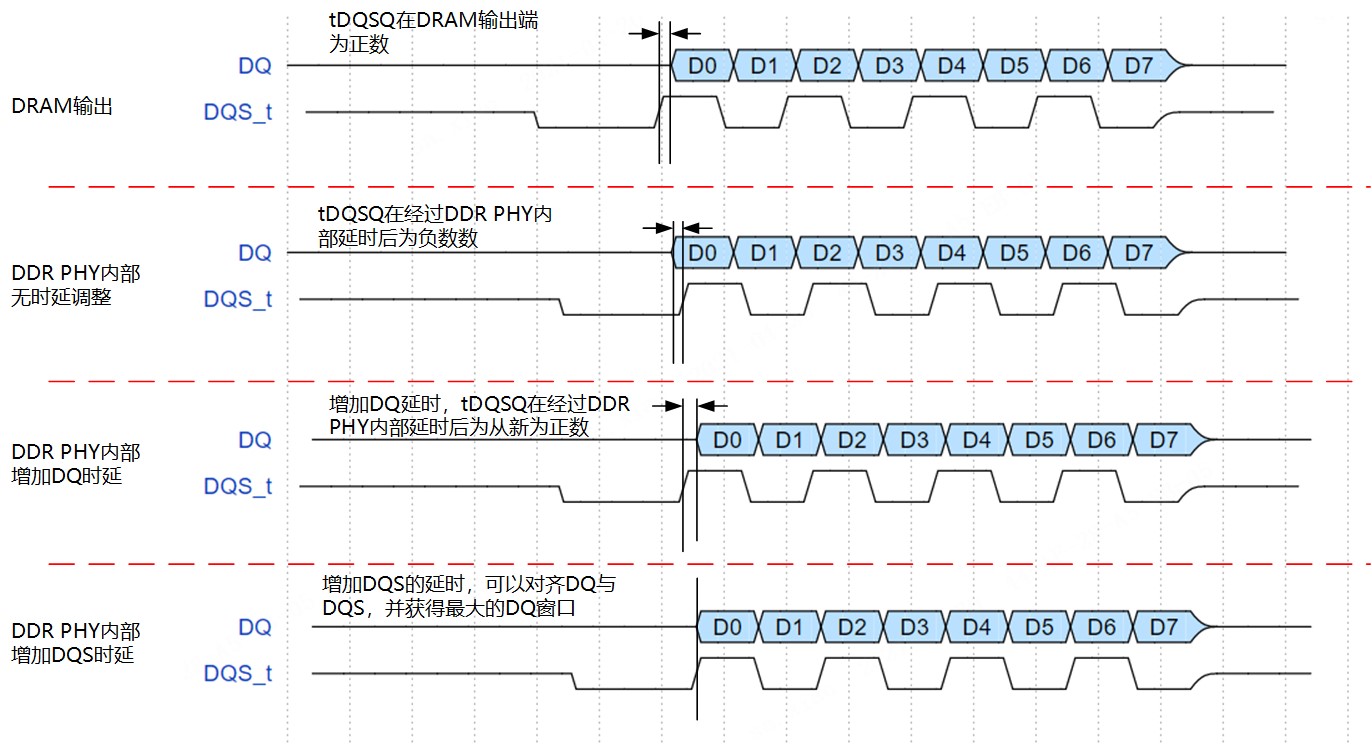
图8:Read DQ skew training
用固件的训练方法获取读数据眼图(Read data eye)的优化值
读数据眼图训练通过延迟读DQS的方法,把读DQS放在DQ窗口的中间。目前最大的问题是固态技术协会标准对读数据眼图的读序列定义的比较简单,比如对于DDR4,定义的序列是01010101的固定序列。因为高速信号的符号间干扰以及信号反射,在不同的读序列的情况下DQ窗口是有差异的,所以采用简单固定的序列并不能很好地覆盖实际的使用场景,导致训练结果在实际工作时并不是一个优化值。
芯耀辉采用固件的训练方法,可以设置不同的范式(pattern),如PRBS范式、特殊设计的扫频范式等。显然此类范式能更好地反映数据通道的特性,因为它包含了高频、中频、低频信息,以及长0和长1带来的码间串扰等问题,可以获得较优的训练结果,从而得到一个能覆盖实际工作场景的可靠值。
二维训练模式下优化的参考电压(Vref)电压和地址线(CA)延迟
LPDDR3中引入了地址线训练,DRAM把采样到的地址信号通过数据通路反馈给DDR PHY,DDR PHY可以通过这个反馈去调节地址线的延迟。在LPDDR4中,还加入了地址线参考电压的训练,所以不仅需要调节地址线的延迟,还需要找到一个最优的参考电压值。传统使用硬件训练的方式在面对这种两个维度的训练时就会显得捉襟见肘,同时硬件算法也没法做得太复杂。
芯耀辉采用固件的二维训练模式,可以绘制出完整的以地址线延迟为横坐标和以参考电压为纵坐标的二维图像,从而得到较优的参考电压和对应的地址线延迟。
二维训练模式下优化的DQ参考电压和DQ延迟
DDR4的固态技术协会标准中引入了DQ参考电压,可是对于如何训练并没有给出说明和支持,所以大多数DDR PHY并不支持DDR4的DQ参考电压训练,只能配置一个固定参考电压值。
LPDDR4的固态技术协会标准增加了写DQS-DQ训练(调整写DQ相对于写DQS的相位)和DQ参考电压训练协议上的支持。
芯耀辉采用固件的方式,不仅支持了DDR4的DQ参考电压训练,同时对于LPDDR4的写DQS-DQ和DQ参考电压训练,也采用了固件的二维训练模式,绘制出完整的以DQ延迟为横坐标和以DQ参考电压为纵坐标的二维图像,在整个二维图像中找到较优的DQ参考电压和对应的DQ延迟。
总结
随着工艺节点的提升和DDR颗粒技术的演进,DDR的工作频率越来越高,DDR颗粒的训练要求也越来越高。同时对于DDR PHY来说,内部的模拟电路(FFE,DFE等)随着频率的提升也需要做各种高精度的训练。芯耀辉采用软硬结合的智能训练方法不仅可以支持DDR颗粒的各种必要的复杂训练,也同时可以支持DDR PHY内部模拟电路的各种训练。通过不断优化训练算法,持续挑战每一代DDR产品的速率极限。
百尺竿头,更进一步,芯耀辉人必将以提供高性能的接口类IP,高品质的设计服务为己任,奋发图强,携手广大芯片设计公司推出更优秀的产品,助力中国芯片产业的发展。

 专利申请
专利申请
 知识产权质押融资
知识产权质押融资
 专利地图分析
专利地图分析
 版权登记
版权登记
 集成电路布图设计
集成电路布图设计
 商标交易
商标交易
 商标申请
商标申请
 专利交易
专利交易
 专利无效
专利无效

【IPO价值观】产品结构单一,环动科技业绩高度依赖埃斯顿



热门评论