北京大学在面向边缘AI的可转置存内计算芯片方向研究取得重要进展


近日,北京大学人工智能研究院类脑智能芯片研究中心唐希源研究员团队在国际电路与系统领域顶级期刊 IEEE Transactions on Circuits and Systems I: Regular Papers (TCAS-I) 发表研究论文,论文题目为“A 28nm 16Kb Bit-Scalable Charge-DomainTranspose 6T SRAM In-Memory Computing Macro”。北京大学集成电路学院博士后宋嘉豪为第一作者,唐希源与集成电路学院王源教授为通讯作者。
随着人工智能的飞速发展,AI在人们生活中起着越来越重要的作用。大量的边缘智能传感器被部署在人们的生活环境中,用于收集数据并自主作出决策。虽然这些智能设备带来了便利,但同时也带来了泄露个人隐私数据的风险。用户通常需要使用个人数据来重新训练或调整模型以适应其个人健康状况或生活习惯。在边缘端的功耗和计算资源限制下,用户仍需将个人数据上传到云端进行模型重训练。如果云服务提供商不可信,则可能导致隐私数据泄露。因此,人们希望能够直接在边缘端完成神经网络的重训练,从而避免将数据上传至云端。
尽管存内计算技术在处理AI推理时因为能够显著减少数据搬运功耗而被广泛使用(图1),但是由于反向传播需要读取模型权重矩阵的转置,传统的存内计算方案无法支持网络训练任务。随着智能应用快速推进,边缘端数据安全与网络训练高功耗、高成本的冲突日益严峻。
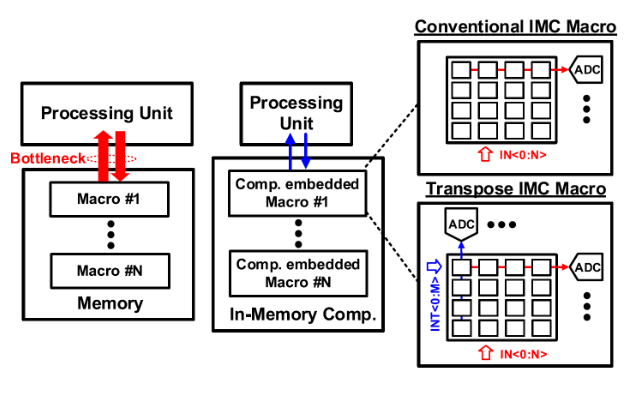
图1. 存内计算架构以及可转置存内计算核的示意图
针对这一挑战,唐希源课题组提出了一种可同时实现高能效模型推断前馈计算与训练反向传播计算的可转置存内计算电路设计,该工作的整体架构如图2所示。
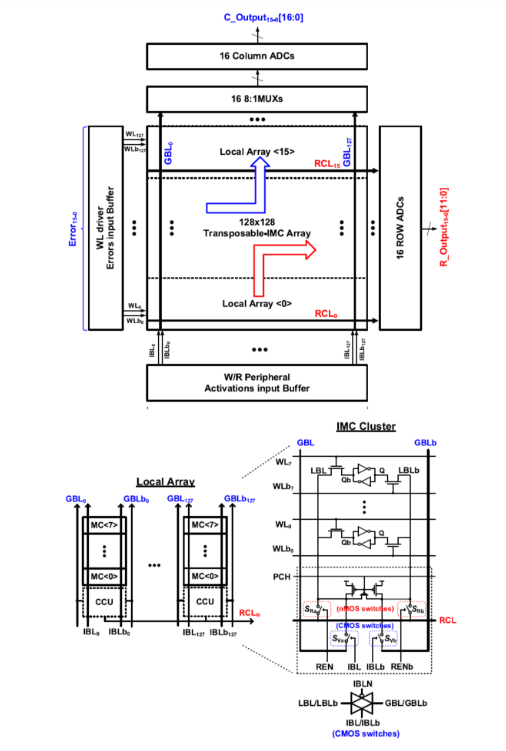
图2. 团队提出的可转置存内计算电路整体架构图与局域阵列示意图
为了在高密度的6T SRAM阵列中支持高精度可转置计算,该工作提出一种基于分簇结构的电荷域局域阵列设计。在分簇结构中,8个6T SRAM单元共用一个电荷域计算单元在位线电容上完成高精度的电荷域计算。因此,该工作的功能单元面积仅为6T SRAM的1.37倍,额外硬件开销很小。此外,该设计可以通过比特串行映射的方法对计算精度进行扩展。如图3所示,课题组基于28nm标准CMOS工艺完成了可转置存内计算电路的芯片原型验证,芯片在前馈计算时的能效达到257.1TOPS/W,在反向传播计算时的能效达到31.8TOPS/W,达到世界先进水平,并在CIFAR-10与MNIST数据集完成性能验证。该技术为边缘端智能提供了低功耗、高鲁棒性的AI加速器解决方案。
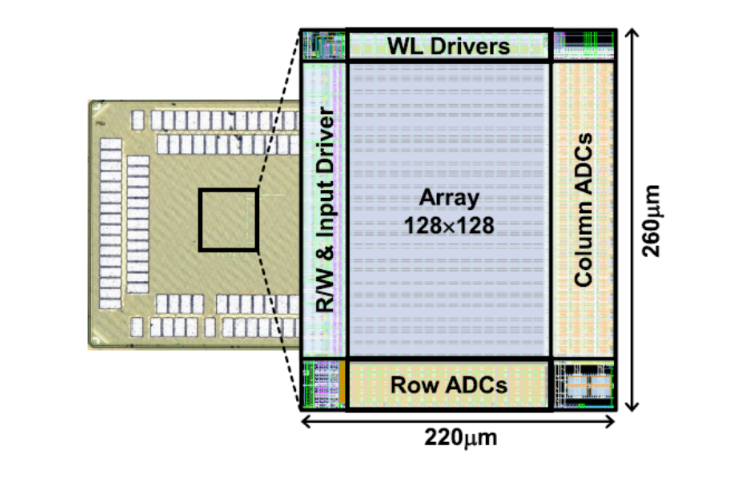
图3. 28nm芯片原型显微图

 专利申请
专利申请
 知识产权质押融资
知识产权质押融资
 专利地图分析
专利地图分析
 版权登记
版权登记
 集成电路布图设计
集成电路布图设计
 商标交易
商标交易
 商标申请
商标申请
 专利交易
专利交易
 专利无效
专利无效

第四批400位嘉宾名单公布!集微大会明日启幕



热门评论