AI掀起高效运算热潮 DSA/DSL后势看好


机器学习(ML)热潮点燃高效能运算需求,新兴运算架构跟着水涨船高。 跟过去数十年流行的通用运算架构不同,这些新兴架构是为了特定几种运算任务优化,并使用特定的程序语言,因而称为领域专用架构(Domain Specific Architecture, DSA)及领域专用语言(Domain Specific Language, DSL)。 DSA/DSL的兴起,将成为引领未来处理器设计,乃至整个半导体产业发展的重要因素。
有信息科学界诺贝尔奖之称的图灵奖(Turing Award),在2018年3月宣布2017年度的得奖者,由David Patterson跟John Hennessey两位研究计算器架构的大师级人物获奖(图1)。 两位学者合着的「计算器组织与设计--硬件/软件接口」,出版至今已有25年,仍是信息工程学界必读的权威著作之一。

图1 2017年度图灵奖得主John Hennessey(右)与David Patterson(左)
两位学者对计算器架构跟微处理器的演进产生非常深远的影响,如精简指令集(RISC)的概念就是由两位学者所提出。 因此,Patterson跟Hennessey早已注定名留青史,获得图灵奖肯定则可说是锦上添花,甚至有些令人意外。
传统上,图灵奖是一个非常偏向软件的奖项,例如人工智能(AI)研究、程序设计理论跟密码学,就是图灵奖的常胜军,很少由跟硬件有直接关系的研究者获得。 因此,两位学者在这个时间点获得图灵奖肯定,加上众多新兴运算架构如雨后春笋般出现,也象征着硬件创新的价值,再度获得各界肯定。
通用架构面临效能/安全双重考验
在过去半个多世纪,制程微缩一直是半导体业者得以降低芯片制造成本、功耗、提升芯片效能最重要的原因,但如今制程微缩已经无法再像过去那样,为芯片供货商带来上述好处。 先进制程的开发费用极为昂贵,而且对功耗跟效能的提升效果已不若过去明显。 即便晶体管尺寸在技术上还有进一步微缩的空间,对芯片商来说,到底值不值得,是个需要精打细算的问题。
Patterson与Hennessey在得到2017年度图灵奖肯定之后,于2018年6月联合发表过一篇公开演说,认为运算架构的发展将进入另一个黄金年代,领域专用架构与领域专殊语言将成为新显学。
两位学者表示,摩尔定律发展面临瓶颈,已经是不争的事实。 不管是内存芯片的密度,或处理器芯片上整合的晶体管数量,都已经无法追上摩尔定律原本预期的目标。 对处理器芯片制造商来说,靠电路微缩来换取芯片效能提升,已经是一条走不通的路,未来必然要从其他创新,特别是架构上的突破来着手。
然而,回顾处理器架构的发展史,通用架构跟通用语言在过去30年来,其实没有突破性进展。 过去30年间,没有任何新的通用型复杂指令集(CISC)的指令集架构(ISA)被提出;通用型超长指令集(VLIW)的ISA则有过一次失败的尝试,即英特尔(Intel)跟惠普(HP)合推的Itanium 64。 归结通用型VLIW失败的原因,主要是因为过于复杂,跟循序超纯量(In-order Superscalar)不相上下,因此在执行复杂应用软件时,没办法带来太多实际效益。
不过,VLIW在嵌入式数字信号处理器(DSP)是成功的,因为这个应用市场对VLIW的需求较为单纯,分支问题相对简单、快取很小或根本没有快取、程序规模也小。 某种程度上,嵌入式DSP其实是一个带有领域专用色彩的处理器架构。 它所要处理的问题范畴相对明确,不像通用型处理器跟通用型语言,要应付各式各样的需求。
相较之下,精简指令集(RISC)无疑是目前最成功的通用型运算架构,目前市面上几乎所有通用型处理器,包含x86处理器在内(更精确来说,是x86指令集兼容),本质上都是RISC。 然而,RISC能为处理器带来的效能成长空间,也已经接近极限,需要更多技术跟架构上的突破,才能进一步提高处理器的效能(图2)。
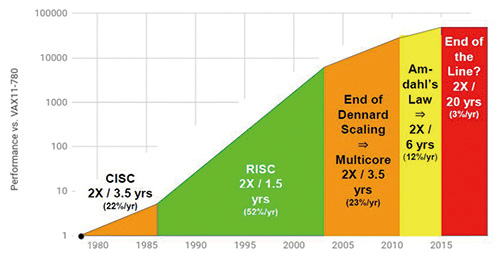
图2 过去40年处理器效能进展概况
除了现有运算架构的效能已经接近极限之外,现有运算架构还面临另一个很大的难题--安全性。 2018年初,Google Project Zero对外公布推测执行(Speculative Execution)漏洞,并有其他研究人员基于此漏洞,发展出熔毁(Meltdown)与幽灵(Spectre)两大类攻击手法。 由于此漏洞普遍存在于现有的处理器架构上,因此英特尔(Intel)、超威(AMD)与安谋(Arm)均无一幸免,且很难用软件予以解决。
Patterson与Hennessey指出,现有的CPU架构其实在接口上非常老旧,因此存在许多攻击向量,英特尔CPU的管理引擎(Management Engine, ME)处理器就是其中之一。 可以预期的是,未来还会有更多基于CPU架构漏洞而发展出来的攻击手法,如果不从架构翻新着手,类似问题将层出不穷。
领域专用型架构/语言将是未来方向
通用型处理器架构跟语言未来的效能发展,显然已经面临困境。 未来芯片业者如何推出效能更强的新产品,来满足市场需求? 两位学者认为,领域专用型的处理器架构跟程序语言,将成为未来发展机会最大的方向。 所谓领域专用型的架构跟语言,分别是指针对特定领域的需求属性客制化的运算架构,以及配合该架构所使用的程序语言。
通用型架构所面临的问题,前文已经有所论述。 通用型程序语言的发展,主要面临的问题在于过度强调程序开发者的开发效率,忽视了程序执行的效率。 从当代脚本式语言的发展就可以看出,程序语言的发展是朝鼓励设计重用(Re-use)、语法更自由的方向发展。 这个方向有助于提高程序开发的效率,但对程序执行的效率却没有太大帮助。
因此,如果要追求更好的效能表现,处理器开发商跟软件社群必须改变思维,针对其锁定的应用发展出优化的架构。 目前领域专用型架构跟领域专用型语言进展最快的应用领域,当属机器学习、计算机绘图跟可编程网络交换器、接口。 这些应用各自孕育出神经网络处理器(NPU)、神经网络加速器、绘图处理器(GPU)等对应的硬件架构,同时也发展出一套自己专用的程序框架或API。
更具体地说,Google的TPU与TensorFlow、GPU与OpenGL的搭配组合,就是领域专用架构跟领域专用语言的实际案例。 TPU跟GPU各自有其适合处理的运算任务,在某几种应用领域内,搭配专用的软件语言,可提供极佳的运算效能;但如果离开其所擅长的应用领域,其整体效能表现就会大打折扣。
而这也意味着DSA跟DSL的发展必须相互依存,如果DSL的发展独立于DSA之外,虽然可以有比较好的灵活度,但通常是以牺牲执行效能作为代价。 TensorFlow就是独立于TPU之外发展起来的DSL,因此在执行效率上还有可改善的空间。 这也促使Google决定自行发展XLA编译程序,以提升TensorFlow执行效率。
大量新创公司拥抱领域专用概念
事实上,两位学者所提出的方向,是科技业内许多厂商在过去几年一直追求的目标,特别是半导体领域的新面孔,其领域专用的产品布局方向非常明显,如自行开发TPU的Google,以及正在大力挖角各方好手, 也想开发自有AI芯片的Facebook,以及中国的百度、阿里巴巴,都是朝领域专用处理器的方向进行布局。
除了网络大厂,半导体新创公司普遍也是以领域专用作为产品布局的主要策略,特别是中国的芯片设计公司,在人工智能、机器学习的浪潮下,普遍以神经网络加速器作为创业题目或未来发展重点。
明导国际(Mentor)执行长Walden Rhines(图3)就指出,半导体购并浪潮冷却后,现在半导体领域的新创公司又开始大为活跃,并获得创投基金大量挹注。 根据明导汇整多家研究机构与自身研究团队的数据指出,AI跟ML是2012~2018年期间,创投基金对半导体新创公司挹注金额最多的应用领域,总金额达到11.63亿美元(图4)。

图3 明导国际执行长Walden Rhines认为,DSA将成为未来处理器发展不可忽视的主流。
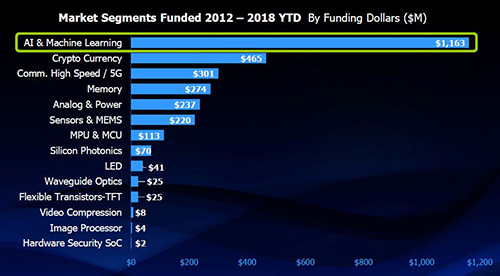
图4 2012~2018年全球创投基金对半导体新创公司投资金额概况
如果只看2018年,仅14家AI/ML新创公司从创投取得的资金,就高达7.86亿美元。 AI/ML成为爆红创业题材的情况,由此可见一斑。 这些AI/ML新创公司都是采用领域专用架构来开发芯片的企业,具体产品则是神经网络加速器或神经网络处理器。
软硬件共同设计考验老将新秀
大量新面孔带着新的题目加入半导体产业行列,对产业发展是好事。 但从现实面来看,创业成功的机率本来就不高,即便是选择市场机会大的题目,辅以合乎产业发展潮流的产品策略来创业,失败的风险也不低。 以DSA跟DSL为例,要开发这种产品,设计团队必须非常了解应用需求,DSL跟相关编译程序技术要有一定的掌握度。 此外,硬件架构的设计原则跟实作等硬件开发的基本功,也是成功不可或缺的关键。
以此进一步分析,大型网络公司本身就是用户,同时又是软件起家,因此前两项要素的掌握度较高,至于硬件开发相关环节,则较为欠缺,必须靠挖角或购并来建立硬件团队。 新创公司则通常是以硬件架构或编译程序作为核心能力,但实作跟应用需求的掌握度较低,必须尽快补足。
至于现有的芯片设计公司,在硬件设计方面具有优势,但对于新兴的DSL通常掌握度较低。 如何招募到相关人才,强化对新兴语言的支持性,或许是最大的考验。
直言之,在DSA/DSL大行其道的未来,软件跟硬件必须同步发展,相辅相成。 纯软件或纯硬件公司,恐怕都得因应此一趋势的转变,及早规划转型对策。

 专利申请
专利申请
 知识产权质押融资
知识产权质押融资
 专利地图分析
专利地图分析
 版权登记
版权登记
 集成电路布图设计
集成电路布图设计
 商标交易
商标交易
 商标申请
商标申请
 专利交易
专利交易
 专利无效
专利无效

晶圆产能释放利好,溅射靶材三厂竞速



热门评论