NVIDIA H100 首秀 MLPerf ,再次刷新性能标杆


昨日 MLCommons 公布了 MLPerf Inference v2.1 的最新结果,在结果中首次出现了 NVIDIA 采用 Hopper 架构的 NVIDIA H100 Tensor Core GPU。而 NVIDIA H100 GPU 首次亮相就在所有工作负载推理中创造了世界记录。

作为 Hopper 架构的一部分, Transformer 引擎采用 16 位浮点精度和 8 位浮点数据格式并整合先进的软件算法。可大幅加速 AI 训练,在不损失准确性的情况下可获得最高 6 倍的性能。这使得 NVIDIA H100 GPU 在运行 MLPerf AI 模型中规模最大、对性能要求最高之一的 BERT 模型上,表现出色。
NVIDIA 表示,相较于 NVIDIA Ampere 架构,NVIDIA Hopper 架构的性能要高出 4.5 倍。在本轮测试中,其提高了所有六个神经网络中的单加速器性能标杆。
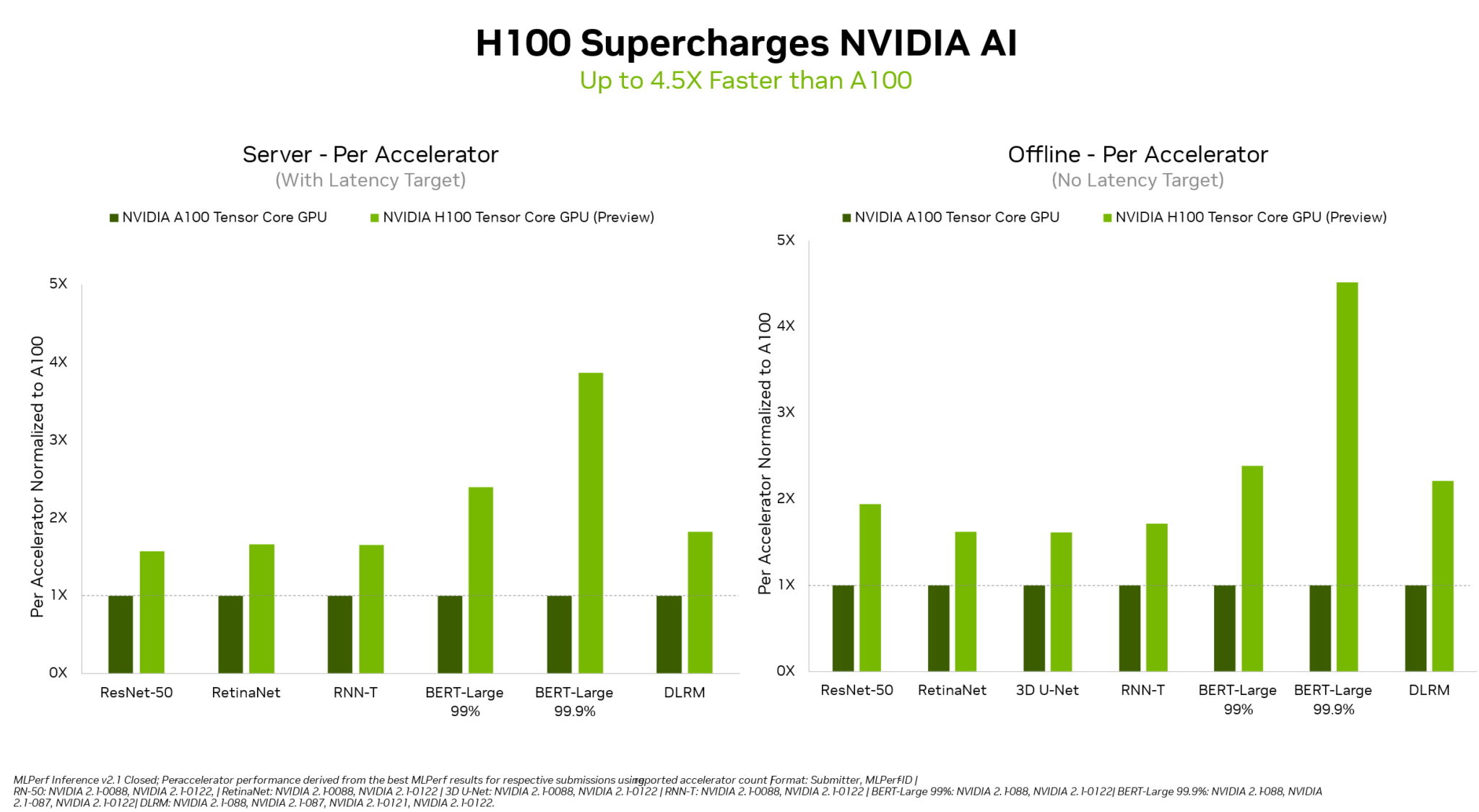
此外,在今年六月 MLPerf AI 基准性能竞赛中大放异彩的 NVIDIA A100 GPU 在此次测试中,依旧在主流 AI 推理性能上实现了全方位领先。例如在数据中心和边缘计算场景中,NVIDIA A100 GPU 赢得的测试项超过了所有其他提交结果的总和。
得益于 NVIDIA AI 软件的持续改进,NVIDIA A100 GPU 在 MLPerf 亮相的2 年来性能已经提升了 6 倍。
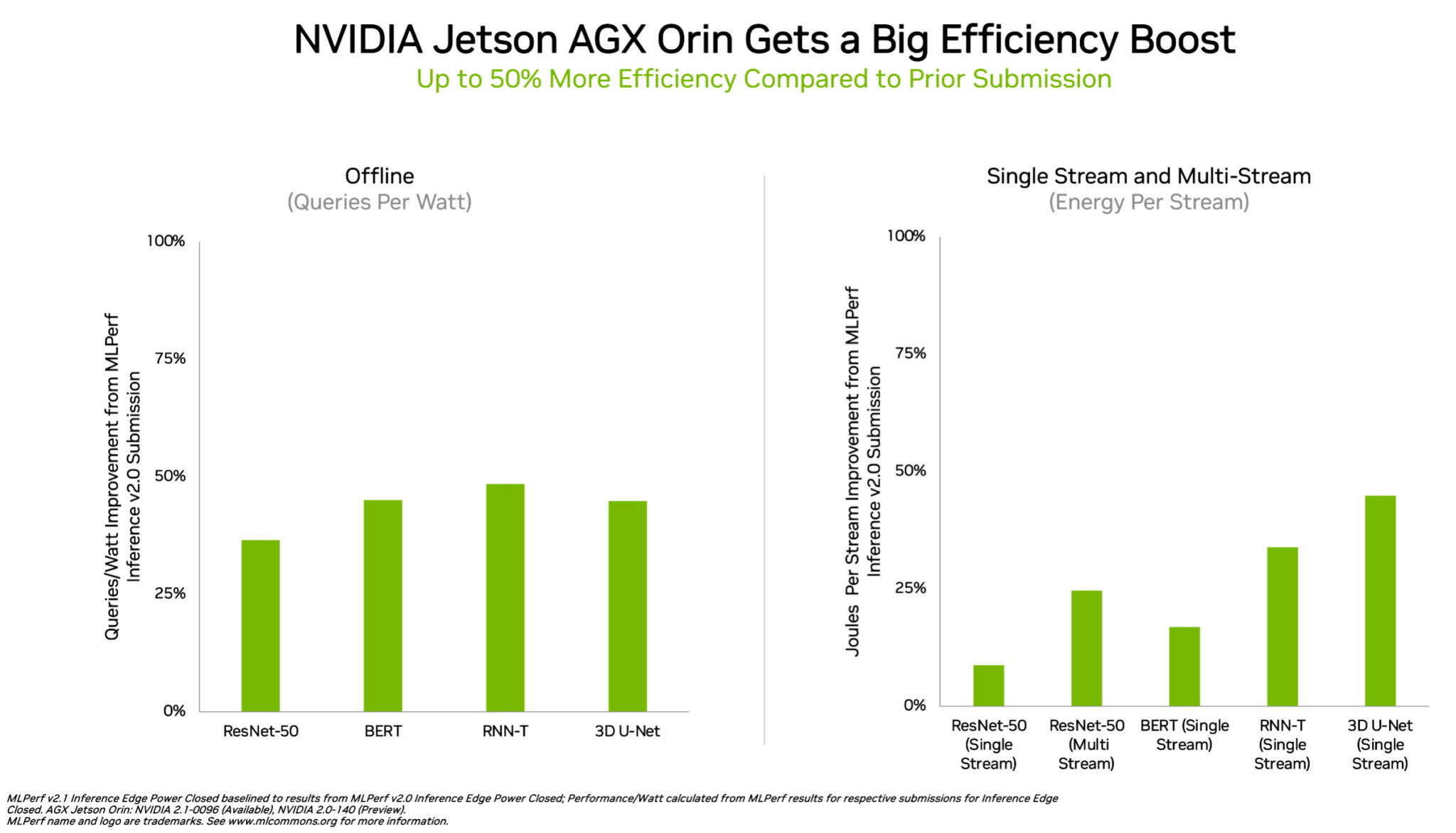
而低功耗级芯片 NVIDIA Orin 相较于今年 4 月在 MLPerf 的首次亮相,能效提高了 50%,是所有低功耗级芯片中赢得测试项最多的。
(校对/邓颖珊)

*此内容为集微网原创,著作权归集微网所有,爱集微,爱原创
 专利申请
专利申请
 知识产权质押融资
知识产权质押融资
 专利地图分析
专利地图分析
 版权登记
版权登记
 集成电路布图设计
集成电路布图设计
 商标交易
商标交易
 商标申请
商标申请
 专利交易
专利交易
 专利无效
专利无效

【IC博览会】全球半导体分析师大会邀您再聚鹏城,共探未来5年产业航向!



热门评论