

【嘉勤点评】芯动力发明的神经网络权值存储及读取方案,在系统初始化时就将神经网络首层的权值固化在静态随机存取存储器的静态内存中,有利于解决循环缓存上溢和下溢的问题,从而使芯片达到较优的吞吐量,也可以降低芯片的功耗和成本。
集微网消息,随着AI芯片的计算能力越来越强,以及神经网络模型越来越深,AI处理器在进行训练或推理时,需要读取大量的权值数据用于计算,而大量的数据吞吐,无疑会降低AI芯片的运算能力。
为了降低芯片的功耗和成本,相关人员在神经网络权值存储方面做了深度研究,目前主流的存储方案有高速DDR(双倍速率同步动态随机存储器)结合Cache缓存或者采用超大容量的SRAM(静态随机存取存储器),进一步还有采用乒乓缓存的方案。
然而,上述方案仍然存在种种弊端,比如传输带宽大、存储占用空间大或者难以使芯片的吞吐量达到较优状态,导致芯片的功耗和成本居高不下。
为此,芯动力在2021年5月7日申请了一项名为“神经网络权值存储方法、读取方法及相关设备”的发明专利(申请号:202110498031.4),申请人为珠海市芯动力科技有限公司。
根据该专利目前公开的相关资料,让我们一起来看看这项技术方案吧。
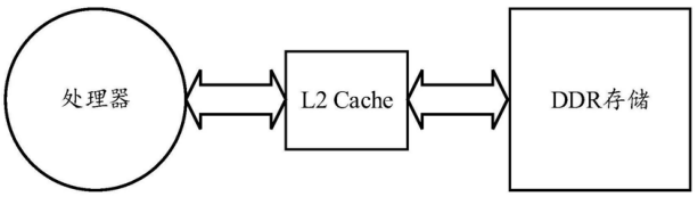
首先,让我们来看看目前现有技术中的神经网络权值存储和读取方案是怎么样的,如上图所示,在神经网络权值存储方面,现有技术提出了高速DDR存储结合L2Cache(二级缓存)的方案。神经网络各层的权值存储在DDR中,处理器在计算时,通过高速DDR接口把待处理的权值加载到Cache中,但是,在处理器计算能力越强的情况下,该方案所需的DDR传输带宽也就越大,不利于降低芯片的功耗和成本。
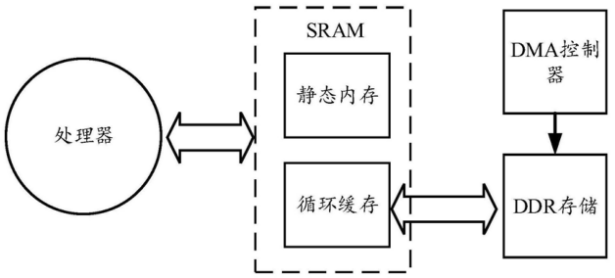
为此,上图为该专利中发明的神经网络权值存储和读取架构的示意图,该架构包括:处理器、小容量的SRAM、DDR和DMA控制器。其中,SRAM被划分静态内存和循环缓存两块存储区,静态内存用于固化神经网络中的出现下溢的层,循环缓存用于预取和存储神经网络中未出现下溢的层。
DMA控制器用于从DDR中读取神经网络权值并向循环缓存中写入读取的权值,处理器用于从静态内存或循环缓存中读取权值以进行计算,比如GEMM(通用矩阵乘)运算等。
在该结构中,会把出现缓存下溢的神经网络层的取值固化到静态内存中,有利于解决循环缓存下溢的问题,当神经网络各层中不存在出现下溢的层时,将获取到的对应权值累积长度的最大值设定为循环缓存的最大存储空间,从而有利于解决循环缓存上溢的问题。并能够以较小的SRAM空间和较低的DDR传输带宽达到芯片较优的吞吐量,以降低芯片的功耗和成本。
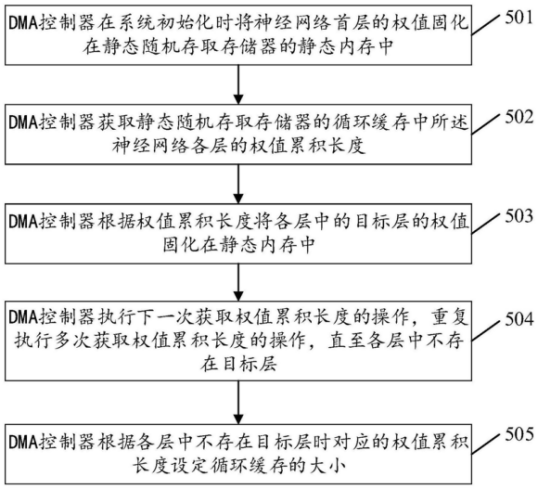
最后,上图为这种神经网络权值存储方法的流程示意图,DMA控制器在系统初始化时将神经网络首层的权值固化在静态随机存取存储器的静态内存中,并获取静态随机存取存储器的循环缓存中神经网络各层的权值累积长度,将根据权值累计长度将各层中的目标层的权值固化在静态内存中。
DMA控制器执行下一次获取权值累积长度的操作,重复执行多次获取权值累积长度的操作,直至各层中不存在目标层。此时,DMA控制器会根据各层中不存在目标层时对应的权值累积长度设定循环缓存的大小。
以上就是芯动力发明的神经网络权值存储及读取方法,该方案在系统初始化时就将神经网络首层的权值固化在静态随机存取存储器的静态内存中,有利于解决循环缓存上溢和下溢的问题,从而使芯片达到较优的吞吐量,也可以降低芯片的功耗和成本。
关于嘉勤

深圳市嘉勤知识产权代理有限公司由曾在华为等世界500强企业工作多年的知识产权专家、律师、专利代理人组成,熟悉中欧美知识产权法律理论和实务,在全球知识产权申请、布局、诉讼、许可谈判、交易、运营、标准专利协同创造、专利池建设、展会知识产权、跨境电商知识产权、知识产权海关保护等方面拥有丰富的经验。
(校对/holly)


