近日,复旦大学集成芯片与系统全国重点实验室有4篇论文被ISCA 2026会议接收录用,研究主题涵盖智能感知/计算/存储、异质异构集成等方向,展现了全国重实验室在高性能芯片体系结构前沿领域的持续创新能力。
ISCA(International Symposium on Computer Architecture)是计算机体系结构领域的顶级国际会议,汇聚全球最前沿的处理器、存储和加速器设计研究成果。自1973年创办以来,ISCA长期代表着全球计算机体系结构研究的最高学术水平,被广泛视为该领域的旗舰会议。ISCA 2026会议的录用率约为19%,预计将于2026年6月27日至7月1日在美国召开。
1.NS-FPS: Accelerating Farthest Point Sampling via Neighbor Search in Large-Scale Point Clouds
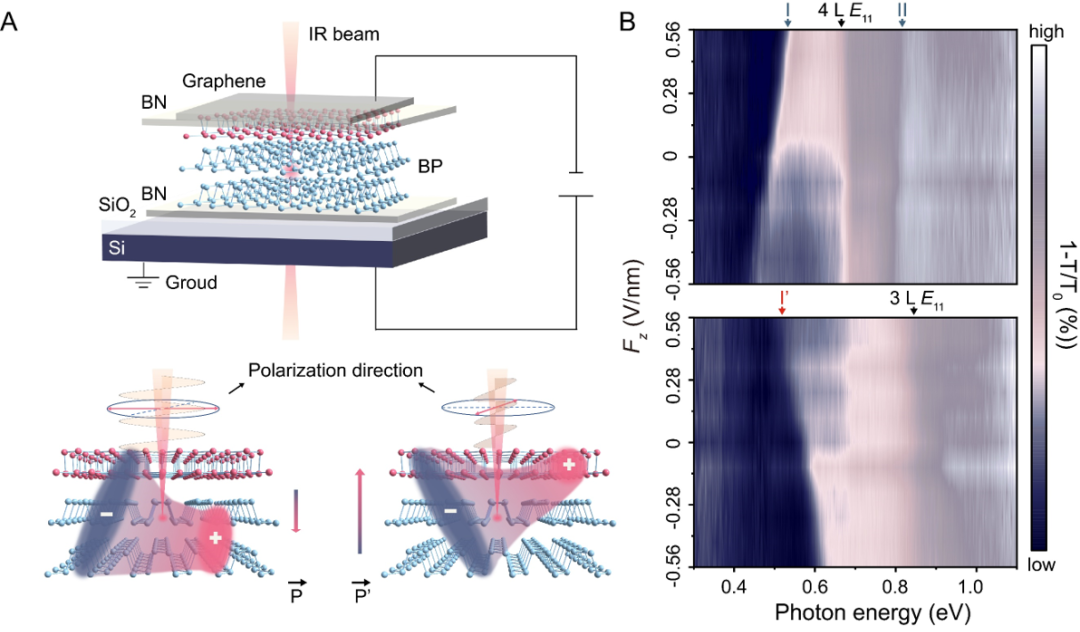
针对自动驾驶等场景中大规模点云处理的性能瓶颈,该研究提出了一种基于邻域搜索的最远点采样加速方法 NS-FPS。该方法结合维诺图几何特性,充分利用采样过程的空间局部性,将传统最远点采样(FPS)转化为迭代邻域搜索问题,从理论上将算法复杂度从O(N2)降至O(NlogN)。同时,本文设计了融合莫顿码空间划分、流水线邻域搜索引擎与分层最大值缓存的专用 ASIC 加速架构,构建了软硬件协同优化的大规模点云采样加速框架。在此基础上,NS-FPS 可无缝集成至 PointNet++、PointRCNN 等主流点云神经网络,为 3D 目标检测、语义分割等任务提供高效采样支撑。实验结果表明,与 GPU 实现相比,NS-FPS 在大幅降低内存访问量的同时实现 81.6 倍加速;与现有先进点云采样加速器相比,性能提升 2.9 倍、内存访问量降低 13.4 倍,在大规模点云实时处理场景中兼具高效率与高扩展性。
该论文的第一作者为博士生郑佳培和杨树安,通讯作者为陈迟晓副研究员。
NS-FPS硬件架构
2.TDMSim: Enabling High-Density and Energy-Efficient GPU DRAM Caches with 2D-Materials for Data-Intensive Applications
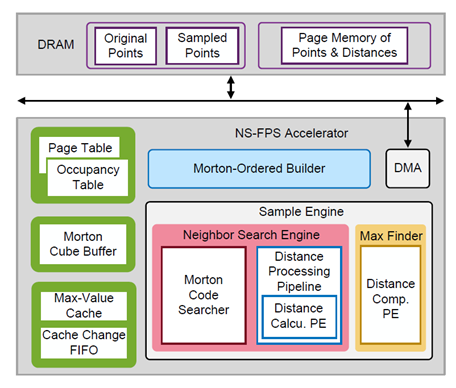
针对新一代人工智能技术对存储容量的急速增长需求,以及传统硅基缓存中存储密度、访问延迟与能耗之间的矛盾,该研究提出了国际上首个面向二维材料缓存的体系结构仿真工具及架构优化方法。首先,针对新型半导体材料缺乏体系结构仿真工具、器件特性难以系统映射至架构优化的问题,该工作开发了一套跨层仿真工具,实现了晶体管级、电路级和系统级的统一建模与分析。基于这套工具,团队进行了多目标设计空间探索,评估各类缓存作为GPU末级缓存的性能潜力,并首次将二维材料DRAM缓存集成至现代CPU-GPU异构计算系统中。其次,针对存储单元在规模集成下表现出的非均一性问题,该工作提出了一种保持时间感知的管理策略,包括刷新调度、循环缓存块布局和热页重映射等,有效延长了刷新时间并优化了缓存访问。实验结果表明,在真实GPU应用负载下,该DRAM缓存相较传统SRAM缓存可实现79.4%的能耗降低与42.1%的性能提升。这将为突破传统缓存架构的性能与能效瓶颈提供新的技术路径。
该论文的第一作者为傅超青年副研究员(绍芯实验室)和硕士生郑靖炀,通讯作者为韩军教授。该论文也是与二维材料与器件领域的交叉研究成果,论文作者还包括周鹏教授、包文中教授。
跨层仿真工具链及体系结构优化示意图
3.GauTracer: Extending Ray Tracing Accelerator for Gaussian-based Scene Representation
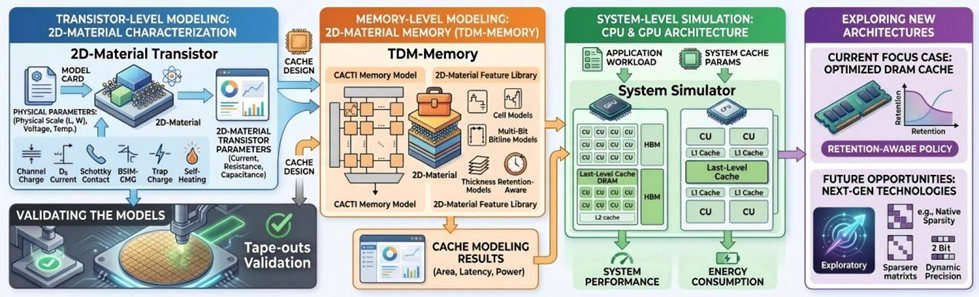
针对当前图形GPU架构中光线追踪加速器(RTA)缺乏对高斯图元原生硬件支持的问题,该研究提出了一种面向高斯场景表示的光线追踪加速器GauTracer。近年来,高斯泼溅技术(GS)凭借显式点云和可训练参数,实现了高保真场景建模与实时渲染。然而,由于传统光线追踪加速器专为三角网格设计,将GS管线集成到光线追踪管线时面临严峻挑战:高斯图元在现有RTA架构中只能依赖软件着色器模拟,由此产生了大量冗余指令与全局内存访问开销。为此,研究团队提出将高斯图元提升为RTA中的一等公民。在硬件架构层面,设计了轻量级微架构扩展和专用光线-高斯求交单元(RGIU),支持3D椭球体和2D椭圆片两种主流表示,通过重构计算数据流实现硬件资源共享。进一步提出基于最大堆的高斯命中单元(AGHU),在寄存器中维护每光线命中缓冲,实现高效的体渲染混合。在遍历优化层面,采用基于树块的BVH遍历方案并引入远节点剪枝机制,有效减少超出缓冲容量的冗余节点访问。实验结果表明,GauTracer相比基线方案,对3D高斯和2D高斯场景分别实现了平均5.8倍和7.3倍的性能提升。该工作通过将高斯图元原生集成到光线追踪加速器中,为高斯场景表示在AR/VR等高级图形应用中的高效部署提供了可行路径。
该论文的第一作者为博士生吴立舟,通讯作者为朱浩哲助理教授。
GauTracer支持高斯图元的光线追踪架构图
4.LoRA: Towards Improved Applicability of Reconfigurable Architecture for Versatile Nonlinear Functions
针对人工智能等新兴应用中大量涌现的复杂非线性函数,本文提出了一种基于切比雪夫多项式的非线性函数近似方法。该方法能充分利用目标函数的代数特性(如奇偶性),为给定非线性函数推导出高精度近似多项式。同时,本文设计了一种基于对数运算系统的计算单元(XCore),将高次幂运算转换至对数域,有效降低了高次多项式计算的硬件开销。在此基础上,本文将上述近似方法集成至粗粒度可重构架构(Coarse-grained Reconfigurable Architecture,CGRA)软件工具链,并将XCore单元嵌入CGRA阵列,构建了支持多种非线性函数的可重构架构研究框架LoRA。实验结果表明,与现有先进非线性函数计算单元相比,XCore在实现更高计算精度的同时,能在图像处理、大模型等应用中提供充分的精度保障,且开销更小;与商用MCU和前沿CGRA研究相比,LoRA CGRA的性能分别提升了23.33倍和2.18倍,能效则较前沿CGRA研究提升了2.13倍。
该论文的第一作者为博士生戴源和硕士生邹桂镔,通讯作者为王伶俐教授。
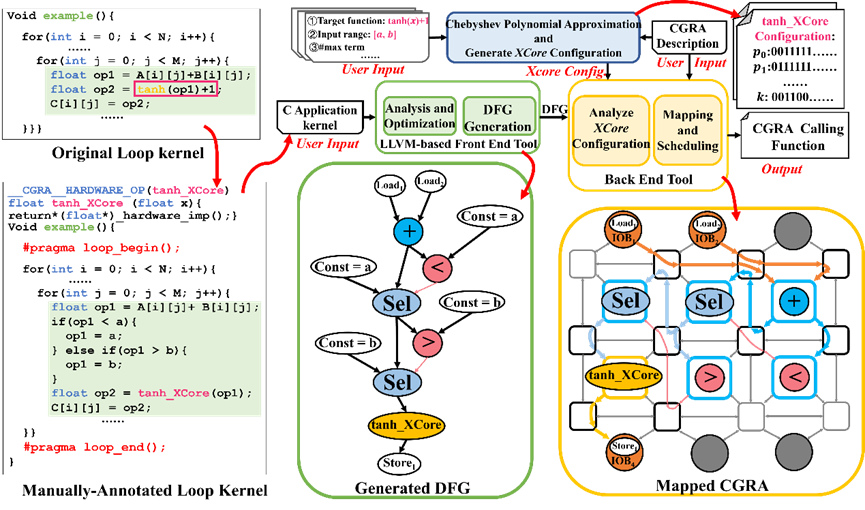
LoRA框架流程图
集成芯片与系统全国重点实验室
集成芯片与系统全国重点实验室是科技部遴选的首批20个标杆全国重点实验室之一,依托复旦大学建设,刘明院士任实验室主任。实验室围绕“集成芯片与系统应用”等任务,下设集成芯片、EDA、IP/架构、超高速电路与系统和未来芯片5个创新中心。