
华中科技大学集成电路学院王兴晟、缪向水教授团队在近日于德国慕尼黑召开的第44届ICCAD会议上报告了基于忆阻器的脉冲存算一体技术最新研究成果“SPARTA: Spike-Aware Token Skipping Co-Optimization with Heterogeneous ReRAM-CIM Architecture for Spiking Transformer Acceleration”。这是华中科技大学集成电路学院在ICCAD会议上发表的首篇论文,标志着我院在脉冲神经网络硬件加速领域取得重要突破。论文第一作者为集成电路学院2023级博士生江品锋,通讯作者为王兴晟教授,华中科技大学是论文唯一完成单位。

脉冲神经网络凭借稀疏脉冲激活特性,在能效优化方面展现出显著优势,成为资源受限场景的理想选择。其中,脉冲Transformer模型兼顾高精度与低能耗,在计算机视觉等领域潜力巨大,但脉冲激活固有的非结构化稀疏性给硬件加速带来严峻挑战:传统存储与计算格式难以适配该特性,导致数据传输与处理开销激增,现有加速器难以充分发挥其能效潜力。同时,脉冲Transformer的网络结构复杂,包含脉冲注意力机制与多层线性层,对硬件架构的兼容性与并行处理能力提出了更高要求

针对上述难题,团队提出了一套算法-硬件协同优化框架,构建了专用异构阻变存储器(ReRAM)存算一体架构,实现脉冲Transformer的高效加速,主要进展如下:
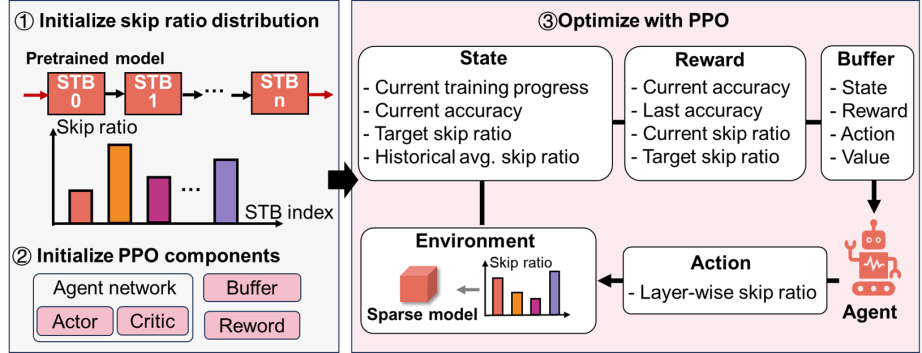
在算法层面,提出基于强化学习的动态token跳过(Reinforcement Learning based dynamic Token Skipping,RL-TS)算法与脉冲感知令牌预测(Spike-aware Token Prediction,STP)算法。RL-TS通过无参数模块动态筛选高价值令牌,在时空维度形成结构化稀疏性,且通过近端策略优化算法自适应调整各层稀疏比例;STP算法通过权重分析设定预测阈值,提前过滤无效token,进一步提升计算效率
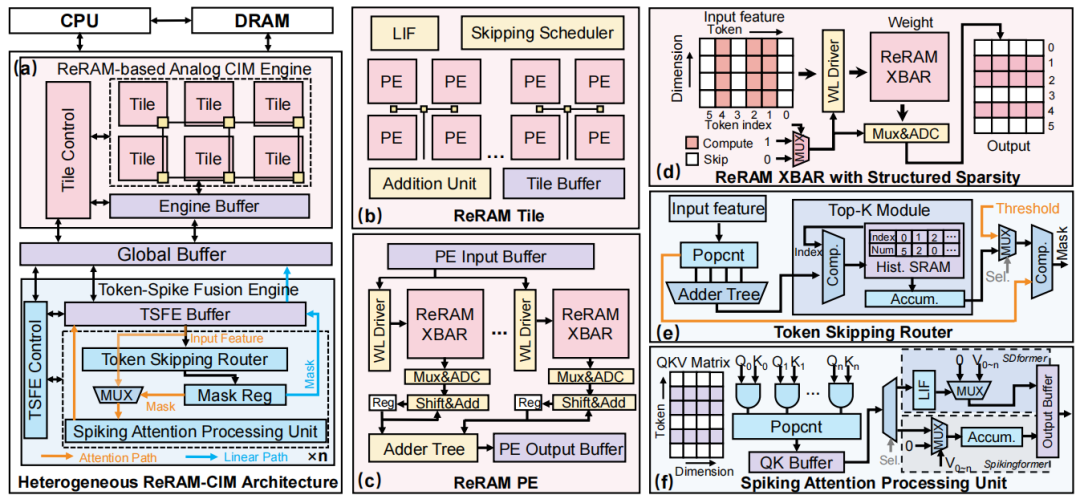
在硬件层面,设计异构ReRAM-CIM架构,包含ReRAM模拟存算引擎与token-脉冲融合数字引擎。前者利用ReRAM高存储密度与原位计算优势,高效处理线性层并行运算;后者通过专用token路由与脉冲注意力处理单元,优化非矩阵类操作,解决传统存算架构对脉冲注意力机制加速不足的问题,两大引擎协同实现硬件利用率最大化。
基于多个基准数据集的测试结果显示,SPARTA架构表现优异,相较于传统GPU,实现高达上百倍的速度与能效提升,且模型精度保持在基线水平,精度损失不超过1.1%。该成果成功突破了非结构化稀疏性带来的硬件效率瓶颈,为脉冲Transformer的边缘部署提供了高能效、高精度的解决方案。
背景导读:
ICCAD(IEEE/ACM International Conference on Computer-Aided Design),全称国际计算机辅助设计会议,由美国计算机协会(ACM)和电气与电子工程师协会(IEEE)联合主办,是全球电子设计自动化(EDA)与集成电路设计领域历史悠久、影响力深远的顶级学术会议之一。会议聚焦芯片设计自动化、存内计算、AI 架构等前沿方向,吸引了全球顶尖科研团队与半导体企业的广泛关注。








