
多模态大模型在通用任务上表现出色,但缺乏细粒度感知能力,如何做到又广(开域泛化能力)又深(细粒度感知能力),是推动大模型从聊天助手到自动驾驶、具身智能、医疗影像、工业制造等实际应用中急需解决的关键问题。针对上述问题,北京大学王选计算机研究所彭宇新教授团队近期取得了一系列重要进展,包括研发并开源了首个细粒度多模态大模型Finedefics、发表首篇细粒度多模态大模型综述论文等。相关成果发表于IEEE TPAMI、CVPR、ICLR等人工智能领域国际顶级期刊和会议,包括CVPR的口头报告论文(接收率3.3%)和亮点论文(接收率13.5%)。
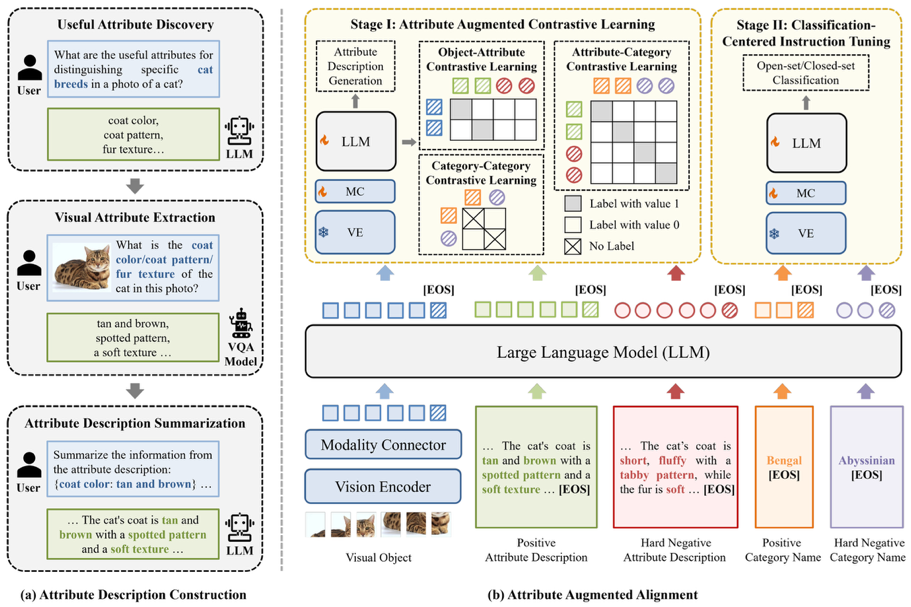
图1. 细粒度多模态大模型Finedefics
针对现有大模型无法准确区分细粒度类别的问题,团队研发并开源了首个细粒度多模态大模型Finedefics,首先通过与大模型的多轮交互构建细粒度子类别的属性知识,然后通过判别-生成统一的指令微调将属性知识分别与细粒度子类别的图像与文本对齐,实现数据-知识协同训练,提高了多模态大模型的细粒度图像分类能力,准确率达到76.84%,相比阿里的通义千问大模型(QwenVL-Chat)提高了9.43%,相比HuggingFace的Idefics2大模型提高了10.89%。本工作发表于人工智能领域国际顶级会议ICLR 2025。
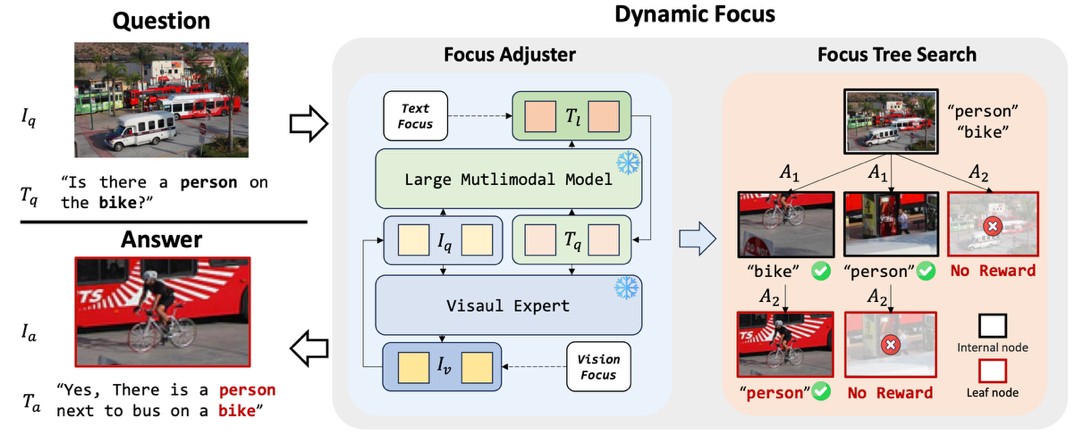
图2. 细粒度视觉推理算法DyFo
针对现有大模型无法准确识别图像中微小目标的问题,团队提出了细粒度视觉推理算法DyFo,通过视觉专家模型与多模态大模型的协同,在无需额外训练的前提下,模拟人类视觉搜索行为逐步聚焦图像关键区域,提高了多模态大模型的细粒度视觉识别能力,准确率达到81.15%,相比阿里的通义千问大模型(Qwen2-VL)提高了8.90%。本工作发表于计算机视觉领域国际顶级会议CVPR 2025,入选大会亮点论文(接收率13.5%)。
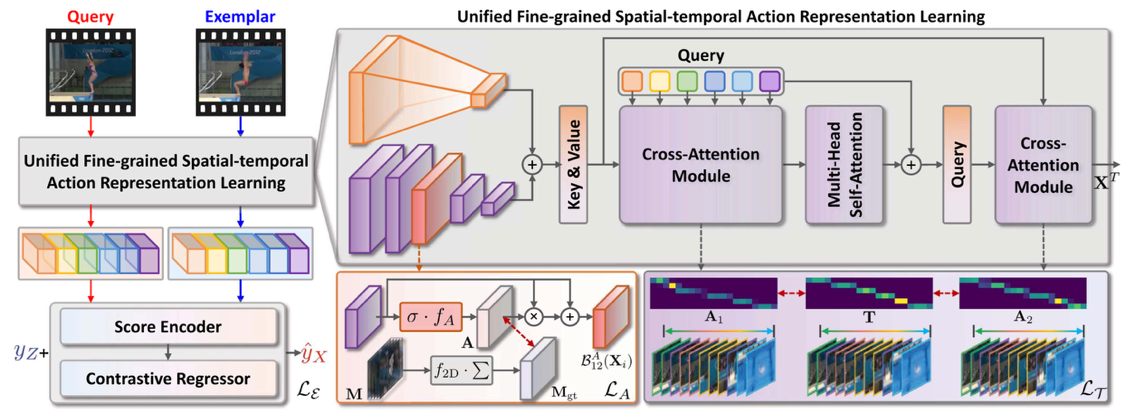
图3. 以人为中心的细粒度人体动作质量评估方法Uni-FineParser
针对运动视频中人体动作难以分析的问题,团队提出了以人为中心的细粒度人体动作质量评估方法Uni-FineParser,通过聚焦前景目标动作区域,提取以人为中心的动作表征,然后通过细粒度对比回归将动作过程分解为连续的动作步骤,量化每个动作步骤的质量,综合各步骤质量差异预测最终动作质量得分,动作得分的斯皮尔曼相关系数达到95.01%。本工作发表于人工智能领域国际顶级期刊IEEE TPAMI(影响因子18.6)。
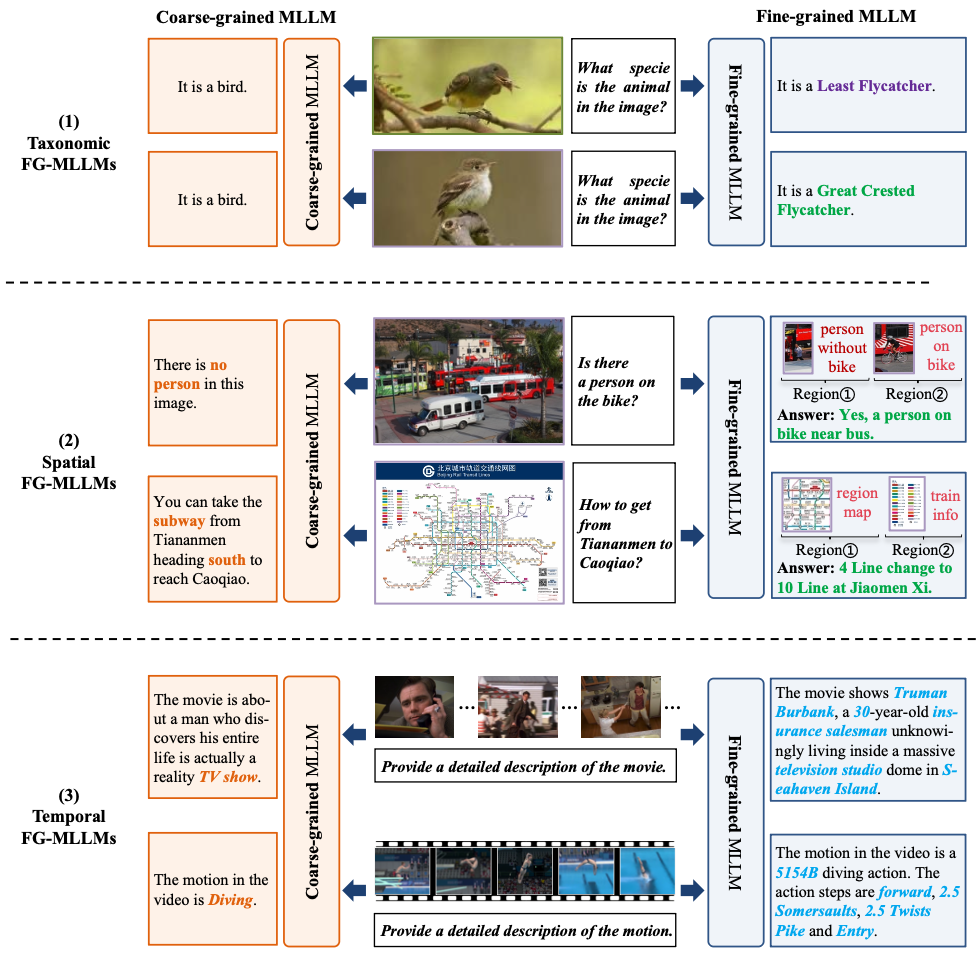
图4. 细粒度感知定义
团队根据在细粒度分析和多模态大模型领域的技术积累与前沿探索,发表了首篇细粒度多模态大模型综述论文,剖析了当前多模态大模型的三大挑战:模型架构在细粒度特征建模上的不足;高质量细粒度标注数据稀缺;细粒度感知与计算效率之间的矛盾。论文从类别、空间、时间3个维度定义了细粒度感知,系统阐述了细粒度多模态大模型的最新研究进展,并深入探讨了精度-泛化-效率权衡、知识增强策略、理解与生成统一、大规模评测基准、细粒度多模态推理等未来发展方向。本工作发表于CJE 2026。
除上述代表论文外,团队近期还取得了如下主要研究成果:团队近期的4篇论文发表于人工智能领域国际顶级期刊IEEE TPAMI,一篇论文入选CVPR大会口头报告(接收率3.3%),3篇论文入选CVPR大会亮点论文(接收率11.8%),两篇论文入选2025年ESI高被引论文;构建并开源了两个细粒度人体运动分析数据集和评测基准FineDiving-HM和FineSports,已被斯坦福大学、英伟达等60多个研究机构使用,团队还研发了首个在国产昇腾处理器上完成训练的生物领域细粒度多模态大模型,并发布到开源社区;团队研发了端侧大模型轻量化、美学理解、大模型强化学习加速、电商广告海报生成、电商短视频生成、自动驾驶障碍物感知等系统,应用于华为、快手、阿里、腾讯、美团、蔚来、中国电信、中国铁塔、中国航天科工三院等12家头部企业;参加CVPR 2025第一视角视频检测竞赛、CVPR 2025多模态视觉问答竞赛、ACM MM 2025视频生成竞赛,均获第一名;彭宇新获2025年青年科学基金项目A类(原国家杰青)延续资助(当年资助期满的杰青项目中不超过20%获延续资助),入选2026年度IEEE Fellow、2025年度CCF会士,当选中国图象图形学学会第九届理事会副理事长,连续5年入选爱思唯尔“中国高被引学者”,主持2025年国家自然科学基金重点项目等。







