
1月19日至22日在中国香港举办的第31届亚洲及南太平洋设计自动化会议(Asia and South Pacific Design Automation Conference, ASP-DAC 2026)上,中山大学虞志益教授、肖山林副教授团队发表突破性成果:首款基于脉冲特征编码的神经辐射场(NeRF)硬件加速器架构,并荣获大会最佳论文提名奖(Best Paper Nomination)。今年ASP-DAC会议竞争激烈,共收到639篇投稿,最终录用176篇,其中仅有14篇文章被提名为最佳论文。中山大学博士研究生高健珍为论文第一作者,肖山林副教授为论文通讯作者。该工作获得国家自然科学基金重点项目和广东省重点研发计划项目的支持。

ASP-DAC会议是集成电路设计自动化(EDA)领域全球著名会议之一,也是亚洲及南太平洋地区在此领域最具影响力的国际学术盛会,由IEEE和ACM联合主办。会议致力于展示在LSI设计、嵌入式系统设计及电子设计自动化等方面的最新研究成果。
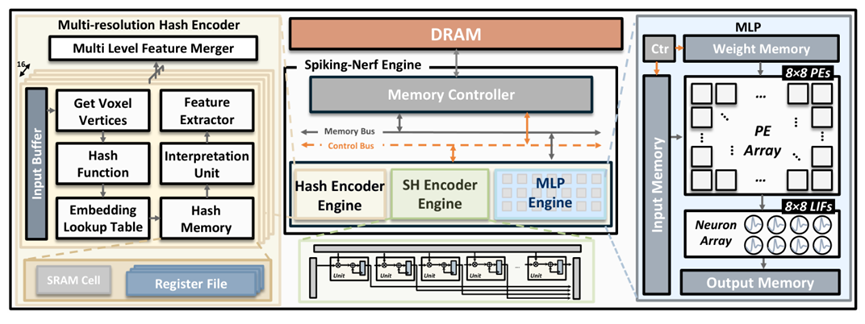
图1 Spiking-NeRF硬件架构
神经辐射场(NeRF)作为一种新兴的3D场景重建与渲染技术,虽然具有极高的渲染保真度,但其多分辨率哈希编码带来的巨大内存需求以及浮点插值运算产生的昂贵计算成本,严重阻碍了其在资源受限的边缘设备上的实时应用。针对这一挑战,团队提出了“Spiking-NeRF”,这是一套基于脑启发式的“算法-硬件协同设计”框架。研究团队通过以下核心创新解决了NeRF推理过程中的存储与计算瓶颈:
1)算法层面: 提出了一种基于积分-发放(IF)神经元的脉冲特征编码机制,将连续的体素特征转化为稀疏的二进制脉冲,相比传统的FP8量化方案减少了75%的哈希存储开销。团队进一步提出了全局重要性剪枝策略,移除了低访问频率的哈希条目,使得存储压缩率额外提升了71.3%。此外,设计了硬阈值权重离散化方法,将复杂的浮点插值乘法转化为简单的位逻辑运算,大幅降低了计算复杂度。
2)硬件架构层面:设计并实现了一款专用的Spiking-NeRF加速器。该架构集成了脉冲跳过机制,能够动态绕过无效的哈希条目,减少了32.46%的冗余内存访问。同时,针对不同分辨率层级的哈希结构,团队协同优化了片上存储方案,利用访问局部性进一步提升了数据吞吐率。
团队采用28nm CMOS工艺对芯片架构进行评估。实验结果表明:Spiking-NeRF在保持高视觉保真度的同时实现了实时渲染。与边缘端GPU相比,该设计在吞吐量上提升了111.2倍,功耗降低了41.67倍;与当前最先进的NeRF加速器相比,Spiking-NeRF实现了高达2.48倍的吞吐量提升和5.45倍的能耗降低。
该工作是国际上首个将脉冲神经网络(SNN)引入NeRF加速并进行联合算法-硬件设计的尝试,证明了脉冲计算在下一代低功耗神经图形系统中的巨大潜力,为移动端、AR/VR等边缘设备的高效3D渲染提供了全新的技术路径。





