随着大模型能力成熟与多模态交互技术突破,AI眼镜不再仅是AR/VR的轻量化分支,而被重新定义为“下一代人机交互核心载体”,用户对AI眼镜的期待,不再满足于只是“听见”,而是期待“从听见,到听得见,到听得清,再到听得懂”四个层级:
能听见——即麦克风完成基础声音采集;听得见——保障音量充足、原声无失真;听得清——实现人声与环境噪声有效分离;听得懂——依托 AI 精准解读用户意图。
如今大部分设备只停留在第二阶段,少数做到了人声降噪分离,真正让 AI 精准理解指令的产品少之又少,全链路系统级协同正在成为行业新标准。
艾为正深挖用户痛点,深度赋能行业头部AI眼镜产品,以“上行采集-中端优化-下行输出-全链路协同”的技术为核心,把这四个阶段全部打通了。布局丰富的产品品类,推动智能音频设备实现从 “能发声” 到 “会感知、懂交互” 的跨越,艾为是如何实现的呢——“上行+下行”算法。
一、AI眼镜上行音效解决方案——帝江™X1
音频上行:声音采集上传
艾为帝江™是艾为推出的上行音频算法系列,针对录音录像,通话等场景,打造多套解决方案,涵盖风噪算法、环绕声、降噪、回声消除、波束成形等核心算法,支持集成至各类主流平台,可根据不同场景需求灵活搭配算法模块,全方位赋能AI眼镜,适配户外出行、会议办公、日常记录等多元使用场景。
1、视频博客(Vlog)场景赋能,无惧运动风噪,人声始终清晰通透
你是否也曾留下这样的遗憾?
骑行途中,风声呼啸盖过内心独白;
跑步跟拍时,喘息与人声混沌难辨;
户外漫步中,环境氛围饱满,却唯独缺了那一句“我想告诉你”的清澈?

图1 运动风噪场景演示
为此艾为帝江™针对AI眼镜全新自研风噪算法:
麦克风阵列采集的声信号经过风噪算法,精准识别风噪,提升语音清晰度,而后通过环绕声模块,提升氛围感,重新定义Vlog的声音美学。
有它在,风大也不怕 ——每一帧画面,都配得上清晰有温度的声音。
状态检测:传递噪声flag
可选模块(被虚线圈中的模块):非必需,适配轻量化需求
已实现(艾为蓝底):已实现模块
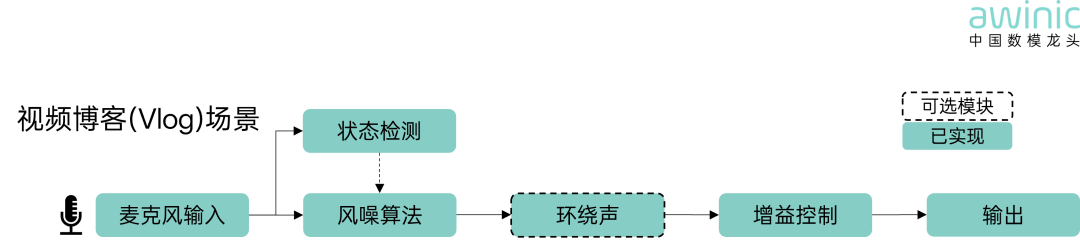
图2 视频博客(Vlog)场景算法框图
效果展示
①风噪算法不同环境下别具一格
无风&小风|智能构建沉浸式环绕声场,让日常对话也自带电影级空间感;
大风|保留环境音,提升语音信号SNR
不是“消音”,而是让人声浮出喧嚣,让氛围沉淀为质感。
②大风场景下风噪算法开关对比
2、全场景通话赋能,智能降噪,人声精准传递
你有没有这样的时刻?
视频会议中,自己说话像隔着一层毛玻璃,同事皱眉问:“你刚才说什么?”
街边接重要电话,背景是车流轰鸣、喇叭长鸣,对方只听见一片“嗡——”;
在国外交流,环境很嘈杂,店员拿起一把菠菜热情介绍:“Do you like spinach?(你喜欢菠菜吗)“,翻译工具识别成“你长得像西班牙人(You look like a Spaniard)”……

图3 翻译场景演示
为此,艾为帝江™深入通话全链路声学现场:
麦克风阵列采集的声信号经过回声消除模块精准剥离回声信号,而波束成形像为声音装上隐形聚光灯,动态锁定声源方向,收束有效拾音区域,最后降噪将外界噪声屏蔽,超低语音损伤带来极致通话体验。
状态检测:传递噪声flag
可选模块(被虚线圈中的模块):非必需,适配轻量化需求
已实现(艾为蓝底):已实现模块
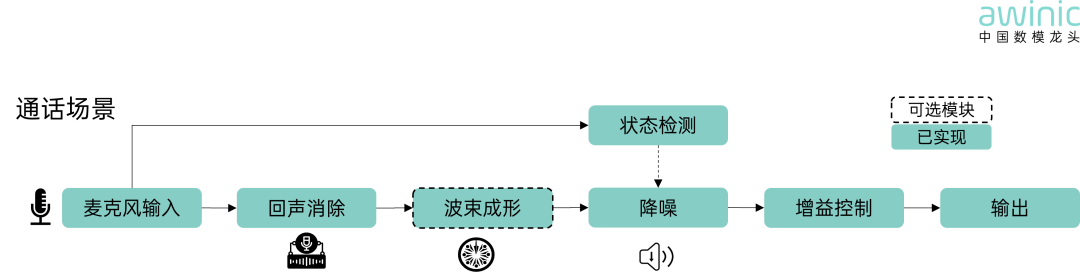
图4 通话场景算法框图
效果展示
回声消除开关对比
回声消除与降噪开关对比
3、唤醒识别的“第一道神经中枢”
你是否也曾经历过这些瞬间?
在地铁里戴着眼镜想问一句天气,风声盖过了你的声音;
在咖啡馆和朋友聊天,刚说“嘿——”,AI眼镜却误判成唤醒;
走路时随口一唤,系统却沉默两秒才反应……
图5 语音唤醒场景演示
于是,艾为帝江™来了。专为AI眼镜而设计的前端语音守门人:
可以在复杂环境(风噪/人声/混响)中提升语音信噪比,真实佩戴场景下,识别稳定性显著提升,字错率下降6%+。
可选模块(被虚线圈中的模块):非必需,适配轻量化需求
计划(灰底):未来规划
已实现(艾为蓝底):已实现模块

图6 唤醒识别场景算法框图
⏳唤醒这件事,早就不是“能叫醒就行”了——叫不醒着急,乱醒来尴尬,反应慢更心累。用户体验才是唯一的裁判。未来艾为将打造超低功耗,超高唤醒率的语音唤醒算法,它会更安静、更敏锐。毕竟,最好的交互,是你根本没意识到它在工作。
音频下行:声音播放输出
AR 眼镜扬声器多置于镜腿,为了美观和便携,腔体空间狭小。器件重量不足2g,尺寸≤10×18mm、厚度≤3.5mm。受物理条件限制,这类微型扬声器音量、低频表现偏弱;双单元独立发声,难以实现环绕声场,同时还易产生明显气流杂音。所以,AI 眼镜播放音乐时,音质单薄乏力,低音缺失,完全没有立体环绕的沉浸感,如何解决呢?

图7 扬声器摆放示意图(单侧)
艾为awinicSKTune®神仙算法W1凭借着极简出色的算法效果,成为解决上述问题的核心关键。
图8 awinicSKTune®神仙算法 W1音效处理
图9 传统音效处理
awinicSKTune®神仙算法 W1可帮助智能穿戴制造商,在紧凑布局设计下呈现更优的低频表现、更低的失真,以及更具沉浸感的音频效果体验。
通过AI元素识别,分离并控制不同音频成分,再对虚拟声源位置进行渲染,模拟出声音从“不同方向、不同距离”传到你耳朵的效果。
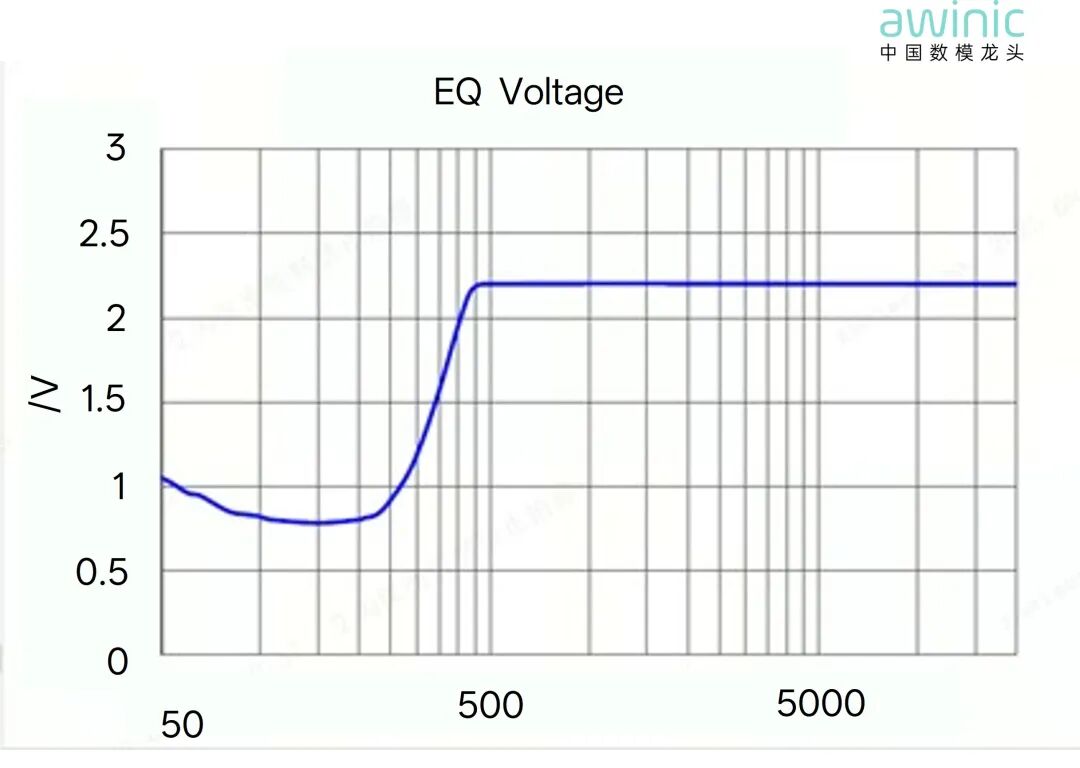
图11 典型AI眼镜的EQ电压曲线
传统的处理手段只能通过EQ中的High pass滤波器或者Low Shelf滤波器进行预处理,以降低低频能量,避免扬声器振膜的机械撞击失真。此方法势必影响了整个低频效果,特别是50Hz-200Hz的重要频段。
awinicSKTune®神仙算法 W1的Bass增强技术能够提供整套完整的低音增强方案:通过建立扬声器的位移模型曲线,确保所有信号均工作在安全振幅范围内,再采用差异的低音增强技术,通过均衡大小信号的虚拟成分听感,提升鼓声人声的低频表现。
由于磁路非线性、支撑系统非线性以及大振幅下分割运动等原因,扬声器在大振幅下容易产生非线性失真问题,导致低频容易产生嗡嗡声,清晰度降低,影响用户听感和低频表现。而非线性失真抑制算法可以修复低频听感,配合bass增强技术,在提升低频动态的同时保持音色纯净。
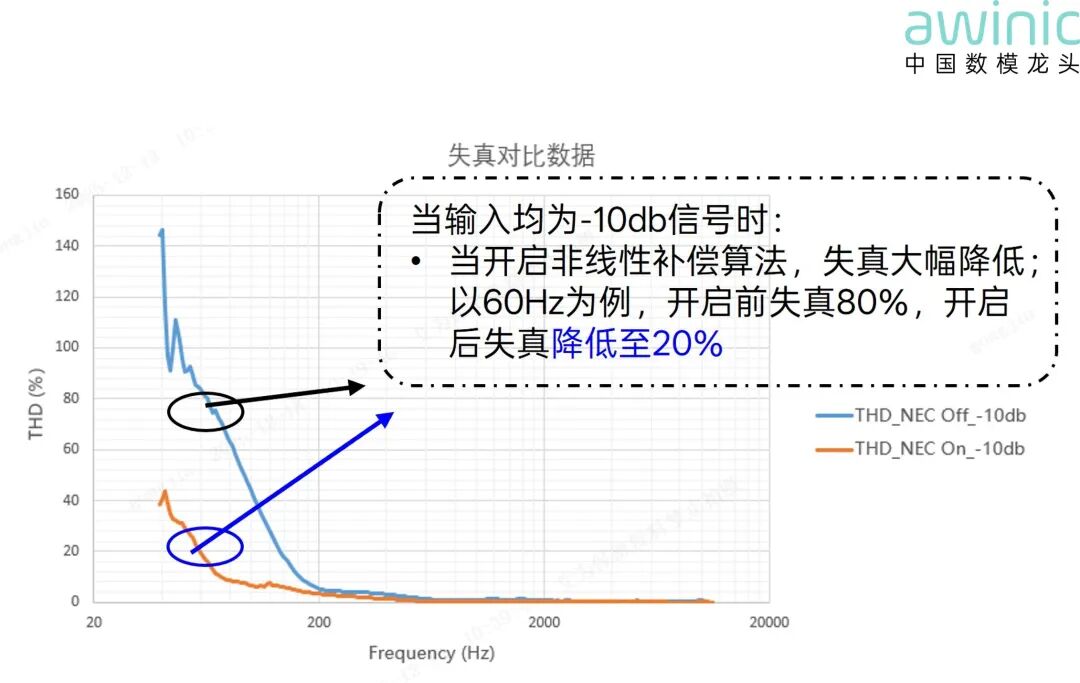
图12 同一输入NEC算法开关失真对比
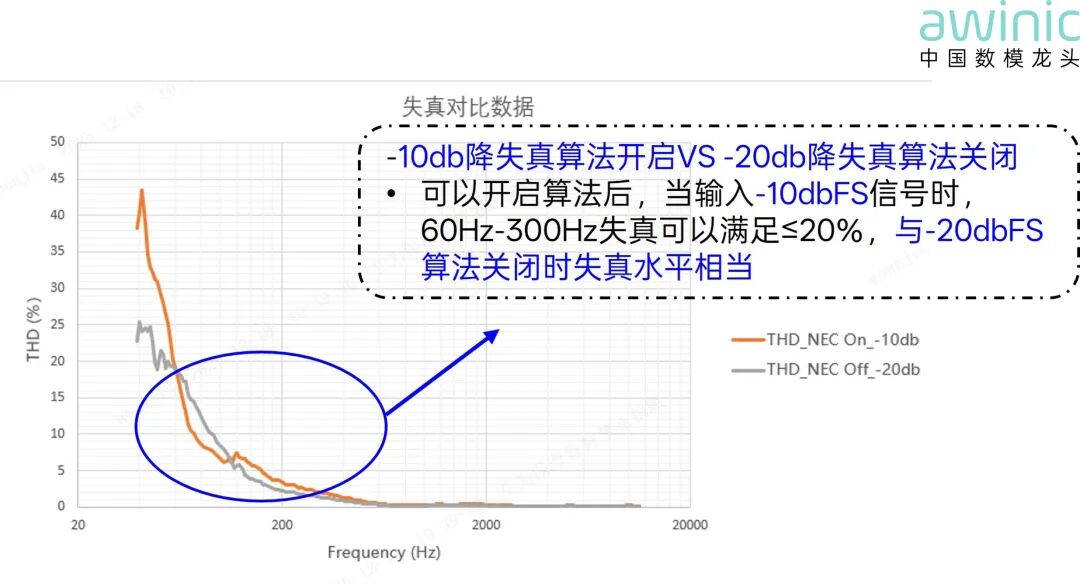
图13 等效失真水平下输入电平对比
awinicSKTune®神仙算法W1的APR技术,可以通过AI智能识别播放音源元素,准确判断音源是否会产生气流杂音,再以灵活的处理手段,在不牺牲其它音源和低音效果的基础上,凭借高达6dB以上的动态压缩能力,解决扬声器气流杂音及钢琴杂音问题。
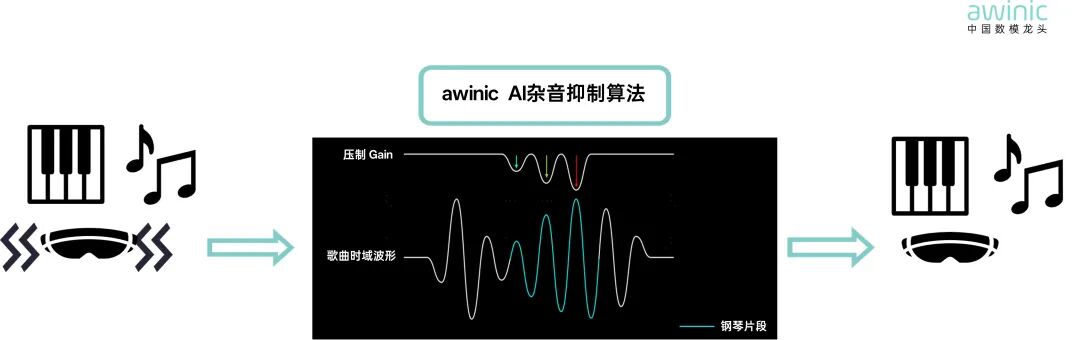
图14 艾为AI杂音抑制算法
户外大音量听不清,室内中小音量低频听感缺失也常常是眼镜产品的一大痛点,awinicSKTune®神仙算法 W1算法的智能音量控制算法可以根据平台侧下发的音量等级信息,实时调整EQ曲线。低音量时,人耳对低频敏感度下降,算法自动提升低频增益;高音量时,为避免喇叭过载,自动降低低频增益并提升中频(人声)清晰度,自动压缩峰值减少杂音。
一键切换,分别调教,让每种场景都有最适合的好声音。
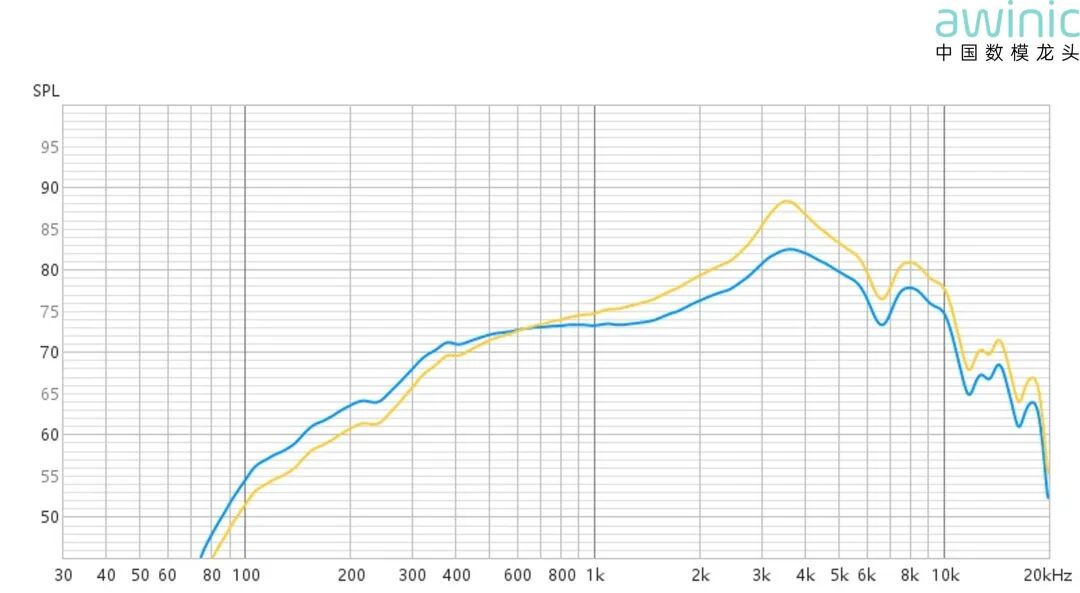
图15 不同模式下调音风格示例
蓝色曲线(室内音质模式):通常用于听音乐等场景,三频均衡,真实还原声音细节与层次感;
黄色曲线(超大音量模式):通常用于户外嘈杂场景,抬升中高频,显著提升语音清晰度与穿透力;
也可以根据需求定义其他想要场景;
此外,awinicSKTune®神仙算法 W1已成功在各大平台实现移植和功能验证,是穿戴类产品首选的音效解决方案。