近日,壁仞科技自研BIRENSUPA™软件栈完成DeepSpeed底层加速器后端完整适配,并合入开源主线,成为DeepSpeed又一原生支持的加速器后端,跻身主流分布式训练框架的硬件生态。
BIRENSUPA™采用标准化插件开发方案,对原有其他硬件后端代码实现零侵入改造;开发者无需修改任何DeepSpeed有关代码,可直接在壁砺™系列GPU产品完整使用DeepSpeed分布式训练、轻量化推理、模型量化等全套优化工具链,实现大模型训推任务跨硬件无感知迁移。
公开信息显示,DeepSpeed是微软推出的深度学习优化库,可便捷、高效地完成分布式训练与推理工作。作为全球主流的分布式优化框架,DeepSpeed兼容多款加速硬件,已被Transformers、Accelerate等主流工具广泛集成,可支持训练不同参数量级的模型。
技术方案:非侵入式适配
得益于DeepSpeed对多种硬件的解耦实现,BIRENSUPA™的接入相对而言对其他硬件影响较小。整套适配遵循一个核心原则——对DeepSpeed现有代码零侵入。本次共新增14个文件、1000+行代码,唯一被修改的存量文件只有一个:加速器自动探测入口accelerator/real_accelerator.py,且仅是“新增分支”,不改动任何已有逻辑。
整体架构可以分为四层:
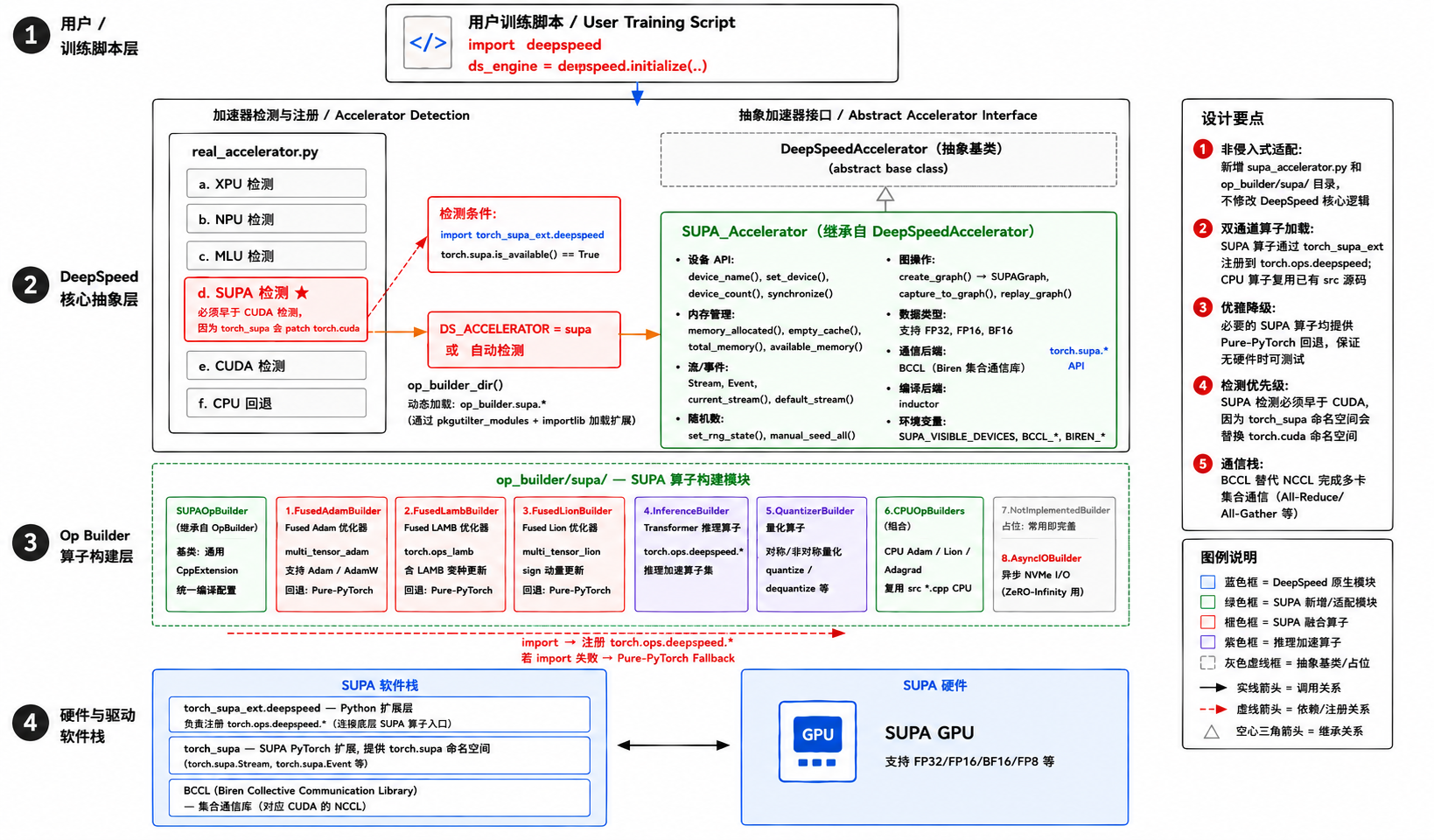
检测顺序的关键细节
由于torch_supa会接管(patch)torch.cuda命名空间,SUPA的探测分支必须早于CUDA检测,否则壁仞卡会被误识别为CUDA设备。这一约束在代码中以注释明确标注,避免后续维护者踩坑。
标准抽象接口,全量对齐
SUPA_Accelerator实现了DeepSpeedAccelerator抽象基类的全部接口——设备管理、内存管理、Stream/Event、随机数、CUDA Graph(映射为SUPAGraph)、编译后端(默认inductor,支持Triton)等,绝大多数 API 直接委托给torch.supa.*,语义与torch.cuda.*一一对应。
双通道算子加载+优雅降级
SUPA融合算子通过torch_supa_ext.deepspeed注册到torch.ops.deepspeed.*;同时,所有import均包裹在try/except中——即使没有编译扩展,模块依然可被导入。融合优化器(Adam / LAMB / Lion)也提供了等价的纯PyTorch回退实现,让无硬件环境下也能做功能验证。
CPU算子源码复用
CPU offload优化器(cpu_adam /cpu_lion/cpu_adagrad)与AsyncIO(ZeRO-Infinity NVMe offload)直接复用DeepSpeed已有的csrc/*源码,不重复造轮子。
通信栈对齐
分布式训练默认使用BCCL(壁仞科技集合通信库) 作为通信后端,对应CUDA生态中的NCCL,完成All-Reduce/All-Gather等多卡集合通信。
开发者无需修改现有用法,零迁移成本
接入对用户完全透明,依旧通过统一的get_accelerator()抽象:
from deepspeed.accelerator import get_accelerator
accelerator = get_accelerator() # 自动返回 SUPA_Accelerator
print(accelerator.device_name()) # 'supa'
device = accelerator.device(0) # torch.device('supa', 0)
tensor = torch.randn(3, device=device) # tensor([...], device='supa:0')
● 自动检测:只要环境里装了torch_supa,无需任何环境变量即可被识别;
● 显式指定:也可通过DS_ACCELERATOR=supa强制启用;
● 多卡可见性:通过SUPA_VISIBLE_DEVICES控制;
● 安全边界:SUPA路径仅在显式指定或检测到torch_supa时才激活,其余任何环境下行为完全不变——对上游CI与其他后端零影响。
DeepSpeed的训练/推理初始化流程无需任何改动,op_builder会自动路由到op_builder.supa。
欢迎前往DeepSpeed官方仓库查看完整实现!
链接:https://github.com/deepspeedai/DeepSpeed/pull/8054