

随着AI大模型时代的来临,市场对于算力的需求将出现爆发性增长。正所谓“经济基础决定上层建筑”,只有当半导体行业能够提供足够便宜的大算力之后,算法和应用才会真正出现突飞猛进的发展。而在后摩尔时代,依靠传统的单一芯片模式,算力已经很难满足算法和应用的需求;而采用板级多芯片互连的模式,也不足以有效解决未来越来越趋于多样化的大模型算法和应用所需要的通用联合计算问题——在可以预见的未来,高性能的Chiplet芯片将是解决这一问题不可或缺的方案。
AI大模型的发展趋势
LLM推动人工智能快速进化到AGI阶段
自2010年代初深度学习问世以来,人工智能进入到第三次高潮。而2017年Transformer算法将深度学习推向了大模型时代。OpenAl基于Transformer的Decoder部分建立起来了GPT家族。ChatGPT一经面世便风靡全球,人们惊讶于其能够进行连贯、有深度对话的同时,也惊异地发现了它涌现了推理、思维链等体现智能的能力。GPT4的能力更是进化神速,在多种能力测试中达到人类顶级水平,让人类看到了AGI的曙光。在向AGI演进的过程中,人工智能将从工具变成人类的伙伴,并将跟随人类的需求进步。
多模态助力大模型解决复杂问题
多模态AI是指能够处理和理解多种类型信息的人工智能,如文本、图像、音频、视频等。这种AI不仅能够处理单一数据类型的任务,而且可以在不同数据类型间建立联系和融合,从而实现一个综合、全面的理解多模态。AI能够对各种不同类型的数据进行关联分析,为解决复杂问题提供支持。未来在诸多创新领域,多模态技术的发展将带来创新应用的蓝海。
生成式AI带来更贴近人的交互方式
从使用键盘-鼠标等方式跟电脑交互,到使用手指滑动屏幕跟手机交互,再到人们用唤醒词跟智能音箱等交互,人机交互从识别机器指令,到识别人的动作,语音,不断朝着更贴近人的习惯的交互方式演进。生成式AI的发展,让人类有史以来第一次有机会用自然语言的方式,来跟机器对话,而机器也借由大模型拥有了极强的理解人类语言的能力,有望带来一场全新的交互变革。 正如历次交互变革带来从终端、到连接,到各类应用的颠覆式变革,生成式Al也必将带来产业链、价值链和生态的重塑。
垂直领域应用是大模型的主战场
随着企业深入开展人工智能重塑各种业务,他们将明确各种场景下最为匹配的人工智能类型。通用AI大模型不一定是满足行业场景需求的最优解。在很多产业场景中,用户对企业提供的专业服务要求高、容错性低,企业一旦提供了错误信息,可能引起巨大的法律责任或公关危机。相对于通用AI大模型,更专注更专业的行业大模型将在产业场景具有广泛应用和商业创新价值。客户更需要有行业针对性的行业大模型,再驾驶企业自己的数据做训练或精调,才能打造成实用性高的智能服务。
AI大模型的应用领域
大模型,也即基础模型,引发了AIGC技术能力的质变。虽然过去各类生成模型层出不穷,但是使用门槛高、训练成本高、内容生成简单和质量偏低,远远不能满足真实内容消费场景中的灵活多变、高精度、高质量等需求。而大模型能够适用于多任务、多场景、多功能需求,能够解决以上诸多痛点。
在消费互联网领域,大模型牵引数字内容领域的全新变革。目前大模型的爆发点主要是在内容消费领域,已经呈现百花齐放之势。大模型生成的内容种类越来越丰富,而且内容质量也在显著提升,产业生态日益丰富。这其中有三个值得关注的趋势:
第一,大模型有望成为新型的内容生产基础设施,塑造数字内容生产与交互新范式,持续推进数字文化产业创新。过去AI在内容消费领域的作用主要体现在推荐算法成为了新型的传播基础设施。推荐算法对数字内容传播,短视频为主的数字内容新业态发展,起到了颠覆式的变革作用。而现在,随着大模型生成的内容种类越来越丰富,内容的质量不断提升,大模型将作为新型的内容生产基础设施对既有的内容生成模式产生变革影响。
第二,大模型的商业化应用将快速成熟,市场规模会迅速壮大。当前大模型已经率先在传媒、电商、影视、娱乐等数字化程度高、内容需求丰富的行业取得重大发展,市场潜力逐渐显现。未来五年10%-30%的图片内容由AI参与生成,有望创造超过600亿以上市场规模。也有国外商业咨询机构预测,2030年大模型市场规模将达到1100亿美元。
第三,大模型还将作为生产力工具,不断推动聊天机器人、数字人、元宇宙等领域发展。大模型技术让聊天机器人接近人类水平日益成为现实,当前以ChatGPT为代表的聊天机器人已经在刺激搜索引擎产业的神经,未来人们获取信息是否会更多通过聊天机器人而非搜索引擎?大模型也在大大提升数字人的制作效能,并且使其更神似人。在元宇宙领域,大模型在构建沉浸式空间环境、提供个性化内容体验、打造智能用户交互等方面发挥重要作用。借助AGIC,元宇宙才可能以低成本、高效率的方式满足海量用户的不同内容需求。
基于大模型技术的合成数据(Synthetic Data)迎来重大发展,合成数据将牵引人工智能的未来。MIT科技评论将AI合成数据列为2022年10大突破性技术之一;Gartner也预测称,到2030年合成数据将彻底取代真实数据,成为训练AI的主要数据来源。合成数据为AI模型训练开发提供强大助推器。过去用真实世界数据训练AI模型,存在数据采集和标注的成本高昂,数据质量较难保障、数据多样化不足、隐私保护挑战等多方面问题。而合成数据可以很好的解决这些问题。使用合成数据不仅能更高效地训练AI模型,而且可以让AI在合成数据构建的虚拟仿真世界中自我学习、进化,极大扩展AI的应用可能性。
在智能驾驶方面,特斯拉借助AI 大模型推出全新感知方案,有效降低成本。随着AI 大模型技术的发展,特斯拉率先采用了基于Transformer 大模型的BEV+占用网络感知算法,提升了环境建模的效率,成为目前主流车企下一代智能化的主要架构。通过这套感知架构能够减少对于激光雷达等高成本传感器的依赖,有效降低系统成本,减轻车企及消费者的负担。目前类似特斯拉的AI大模型感知技术及其延伸得到越来越多车厂的青睐。
AI大模型的主要特点
AI大模型主要体现在多模态和多任务。目前几乎所有大模型都建立在Transformer架构之上。Transformer 模型包括编码器(Encoder)和解码器(Decoder)两个部分。编码器用于将序列转换为一组向量表示,包括多头注意力和前馈,解码器用于将向量 解码为输出序列,包括多头注意力、编码器-解码器注意力和前馈。
Transformer 模型通过注意力机制,整合了CNN 易于并行化的优势和RNN 模型可以捕捉长序列内的依赖关系的优势。神经网络模型可以分为前馈神经网络和反馈神经网络两类:(1)前馈神经网络中,信息从输入层开始输入,每层的神经元接收前一级输入,并输出到下一级,直至输出层。整个网络信息输入传输中无反馈(循环)。常见的前馈神经网络如卷积神经网络(CNN)。(2)反馈神经网络中,神经元不但可以接收其他神经元的信号,而且可以接收自己的反馈信号,常见的反馈神经网络如循环神经网络(RNN)。Transformer 模型利用注意力机制实现了并行化捕捉序列依赖,并且同时处理序列的每个位置的Tokens。因此相对于CNN 模型,Transformer 模型可以捕捉长序列内的依赖关系,相对于RNN 模型,Transformer 模型有更高的并行度,且能保存更多的前期数据。
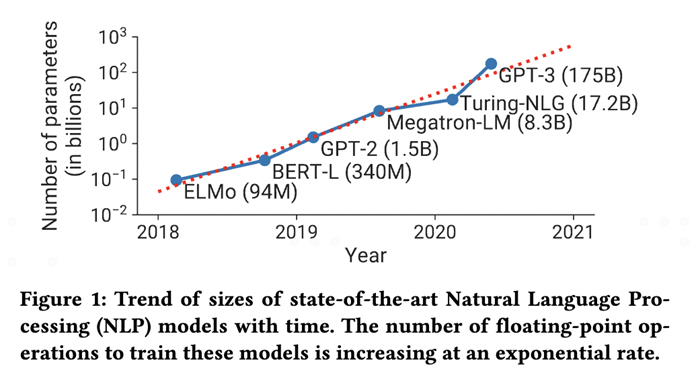
伴随着AI大模型能力的提高,AI大模型的参数量持续增加,训练和推理所需的存储、算力的增长随之变化。故此AI大模型的主要特征可以归纳为以下三点:
参数量庞大:从GPT-1到GPT-3,大模型的参数量从1.1亿激增到1750亿个,GPT-4则达到了万亿级别。如今边缘端的可部署大模型参数量一般在10亿级别,并有望迅速突破百亿级别。庞大的参数量将对芯片的内存及带宽提出更高要求。
运算量庞大:当前的大模型浪潮已经将运算量全面推进至了TFLOPS量级,例如Stable Diffusion这类的模型需要5.5 TFLOPS的运算量,而Point-E更是需要658 TFLOPS的运算量。庞大的运算量级导致原始计算单元的算力需求愈发高涨。
算力需求大:为了训练这些大模型,开发者需要使用超级计算机或分布式计算集群等大量计算资源。据公开报道,训练一次GPT-3模型所需花费的算力成本超过460万美元。
此外,AI大模型不只是对训练资源有极高的要求,对推理资源也有很高的要求。模型推理速度受限于通信延迟和硬件内存带宽,需要在现有计算资源情况下实现低延迟、高吞吐,既满足推理性能要求又节省资源。模型推理内存需求过高,可通过模型/张量并行技术来解决,但过多的计算单元并行,会增加跨单元通信时间和降低每个单元的计算粒度,从而导致最终结果是增加而不是减少延迟(Latency)。进一步的深度分析表明,AI大模型的推理瓶颈,在端侧访存Batch=1的情况下99%是Weights,当Batch>=4时,则是很高的Activation的内存要求。如上所述,大模型的根本是Transformer,而Transformer计算瓶颈是GEMM优化,访存瓶颈则是Self-attention模块。
当前AI芯片大模型解决方案存在的问题
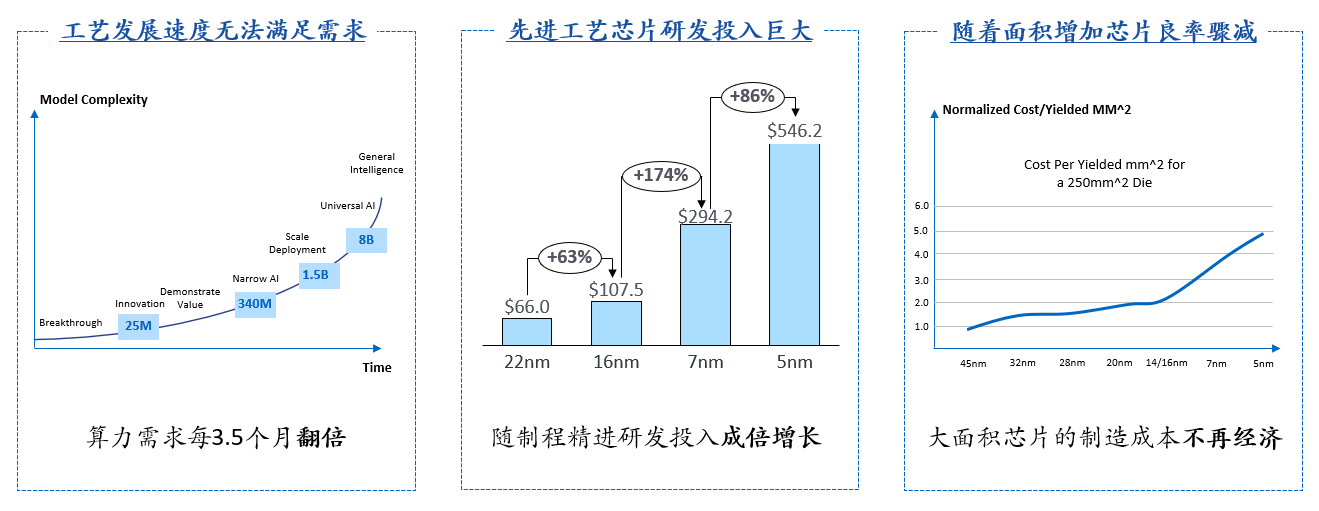
为了满足AI大模型的算力需要,单个原始计算单元(芯片)所需要容纳的晶体管数量呈爆炸性增长,带来的结果势必导致芯片面积的剧增,良率随之急剧下降,这意味着单个计算芯片的制造成本将不断攀升。过去在摩尔定律有效的时代,这一问题可以通过采用先进工艺得到解决,但是如今随着摩尔定律逐渐失效,先进工艺也不再是万灵药了:一来采用先进工艺所需要的研发费用越来越高,二来随着工艺演进,单位良品面积的成本(Cost/Yielded mm^2)的上升速度已经超过了晶体管数量增加的好处。所以,当算力需求增长到一定程度,单个芯片已经不再具备可实现的经济性。
那么,如何才能满足AI大模型的算力需要?要么在系统级采用多颗芯片互连(类似于英伟达的AI计算集群),要么在封装级采用多颗芯粒(Chiplet)互连(类似于AMD的MI300或Tesla的Dojo),这两种方法目前都已经在数据中心上得到了广泛的应用。但是他们是否真的能够满足大模型时代的需要呢?
无论是在系统级还是封装级,只要采用多颗芯片(粒)互连,势必要求将单一AI大模型任务拆解为多个相对较小的任务。这一任务拆分的工作也势必对AI大模型应用的计算效率和反应速度产生负面影响。人们自然会想到:是否有可能让多颗芯片(粒)联合起来工作,就好像一颗芯片一样呢?如果能够做到这一点,当然就可以完美地解决AI大模型的计算效率问题。但是现实情况是,多颗芯片(粒)之间的互连效率很难跟芯片内部的互连效率相比,除非能够将内部总线原封不动地复制到片间互连接口上——这意味着片间接口需要成千上万条连接线,在系统级这样的需求是不可能满足的,而在封装级目前也只有采用类似于台积电CoWoS这样的2.5D/3D先进封装技术的Chiplet才有可能实现。
有人可能会追问,为什么系统级的互连效率很难跟芯片内部的互连效率相比呢?首先,就板级多芯片互连来看,最为常见的是通过PCIe或NVLink这类串行通信接口实现互连。而众所周知的是,PCIe或NVLink这类串行通信接口都存在延迟较大的问题:一方面是由于串行通信自身所具备的包交换(Packet Switching)特点,需要多层通信协议的支持,一般而言这意味着50~100ns级别的端到端传输延迟;另一方面,即便将通信协议简化为数据流传输(Data Streaming)模式,也仅仅能够降低数据传输的延迟,而无法真正将片间互连的效率提升到与片内总线接近的地步。举例来说,AXI的片内总线延迟(例如:从Master发出请求到Slave回复)一般不会超过若个纳秒(或若干个片内时钟周期),这是因为AXI总线所具备的流水线设计。但如果Master和Slave位于两颗不同的芯片中,Master芯片的AXI总线需要被转换到一个数据流传输接口上再与Slave芯片连接,那么在数据传输过程中,总线流水线交互的延迟将会大大增加。具体来说,Master的请求信息被打包后通过数据流接口传输到Slave一侧,需要经过一系列操作予以恢复(这些操作往往还需要软件驱动程序的参与),然后Slave端产生的回复信息也同样会被打包传输到Master 一侧,再经过一系列操作予以恢复,这时才完成了一个最基本的总线交互,期间所产生的延迟将大大超过若干纳秒(或若干个片内时钟周期)。正是由于这个原因,系统级串行通信接口的互连效率将大大低于片内总线互连的效率。从根本上来说,串行通信接口也并非为了实现Chiplet这样的算力扩展目的而设计,所以达不到所预期的效率也在情理之中。
那么,为何在今天的AI大模型训练任务上,人们还可以通过板级互连的计算集群来实现呢?那主要是因为训练任务对实时性要求不高,能够在一定程度上容忍传统串行数据通信接口的高延迟带来的性能损耗。其次,每个原始计算单元(芯片)也会配备足够容量和带宽的片外内存,因此可以把片间数据交互的性能需求降到最低。换句话说,目前的计算集群是通过付出高昂的成本来换取更高的计算性能。即便这样,以英伟达为例,NVLink还是需要通过降低传统PCIe串行数据通信接口带来的延迟来提高片间互连的性能。当进入到大模型推理任务时,实时性的要求就越来越高,对系统成本的需求也会越来越高,此时就更需要通过高带宽,低延迟的Chiplet互连来提升多颗芯片联合计算的性价比,这意味着Chiplet在AI大模型时代已经势在必行。
但是如前所述,要能够在Chiplet上实现足够好的互连效率,就必须在片间互连上实现总线的扩展,而不仅仅是一种简单的数据通信。具体来说,传统的串行通信接口(例如NVLink,UCIe等)在Chiplet上无法满足多颗芯粒的高效联合计算需求,所以无法适应AI大模型时代的需要。事实上,采用传统串行通信接口的Chiplet与板级多芯片互连的联合计算效率没有本质差别,无法真正发挥Chiplet异构集成技术的优势。而如果要将片内总线直接复制到片间互连上来,一般情况下必须采用依赖于2.5D/3D先进封装技术的并行互连接口(例如HBM的接口)。但是,先进封装技术又带来成本高昂、产能不足等一系列问题,对于未来用量不断激增的AI推理业务来说就会成为一个显著的瓶颈。
芯砺智能的专利性D2D片间串行互连接口采用了总线扩展的设计思想,在不依赖于先进封装的前提下实现了高带宽、低延迟的特性,以较低的成本实现了高效的多芯粒联合计算,有效地降低了Chiplet技术的应用门槛,为推动未来AI大模型时代Chiplet技术的大规模运用打下了坚实的基础。
在本系列技术科普文章的下期:AI大模型时代来临,Chiplet算力扩展势在必行 (下),我们将会继续深入本篇话题,续解AI芯片的大模型解决方案的发展趋势及Chiplet技术在大模型时代的无限潜能。





评论
文明上网理性发言,请遵守新闻评论服务协议
登录参与评论
0/1000