

英伟达11月13日正式发布了新一代AI GPU芯片H200,以及搭载这款GPU的AI服务器平台HGX H200等产品。这款GPU是H100的升级款,依旧采用Hopper架构、台积电4nm制程工艺,根据英伟达官网,H200的GPU芯片没有升级,核心数、频率没有变化,主要的升级便是首次搭载HBM3e显存,并且容量从80GB提升至141GB。
得益于新升级的HBM3e芯片,H200的显存带宽可达4.8TB/s,比H100的3.35TB/s提升了43%。不过这远没有达到HBM3e的上限,海外分析人士称英伟达有意降低HBM3e的速度,以追求稳定。如果与传统x86服务器相比,H200的内存性能最高可达110倍。
由于美光、SK海力士等公司的HBM3e芯片需等到2024年才会发货,因此英伟达表示H200产品预计将在2024年第二季度正式开售。
参数方面,H200 GPU目前仅提供SXM 5板卡形态,并兼容此前H100的主板。其中GPU核心预计与H100相同,CUDA核数预计为16896个,Tensor Core张量核心数为528个,GPU加速频率1.83GHz,总晶体管数量约为800亿个,NVLink 4带宽依旧为900GB/s,PCIe Gen5带宽为128GB/s,TDP功耗与H100一致,均为700W。
英伟达表示,通过超高速的NVLink-C2C连接,H200可以兼容此前发布的GH200超级芯片,后者在一块板卡上整合了英伟达自研的Grace CPU、Hopper GPU,同样具备HBM3e高带宽内存。此外,英伟达为这些硬件提供了与之配套NVIDIA AI Enterprise软件套件,便于开发者、企业创建人工智能大模型。
以下为英伟达官网展示的H100参数:

尽管GPU核心未升级,但H200凭借更大容量、更高带宽的显存,依旧可以在人工智能大模型计算方面实现显著提升,支持更多参数大模型,满足更高的工作负载,同时能效方面会有提升。
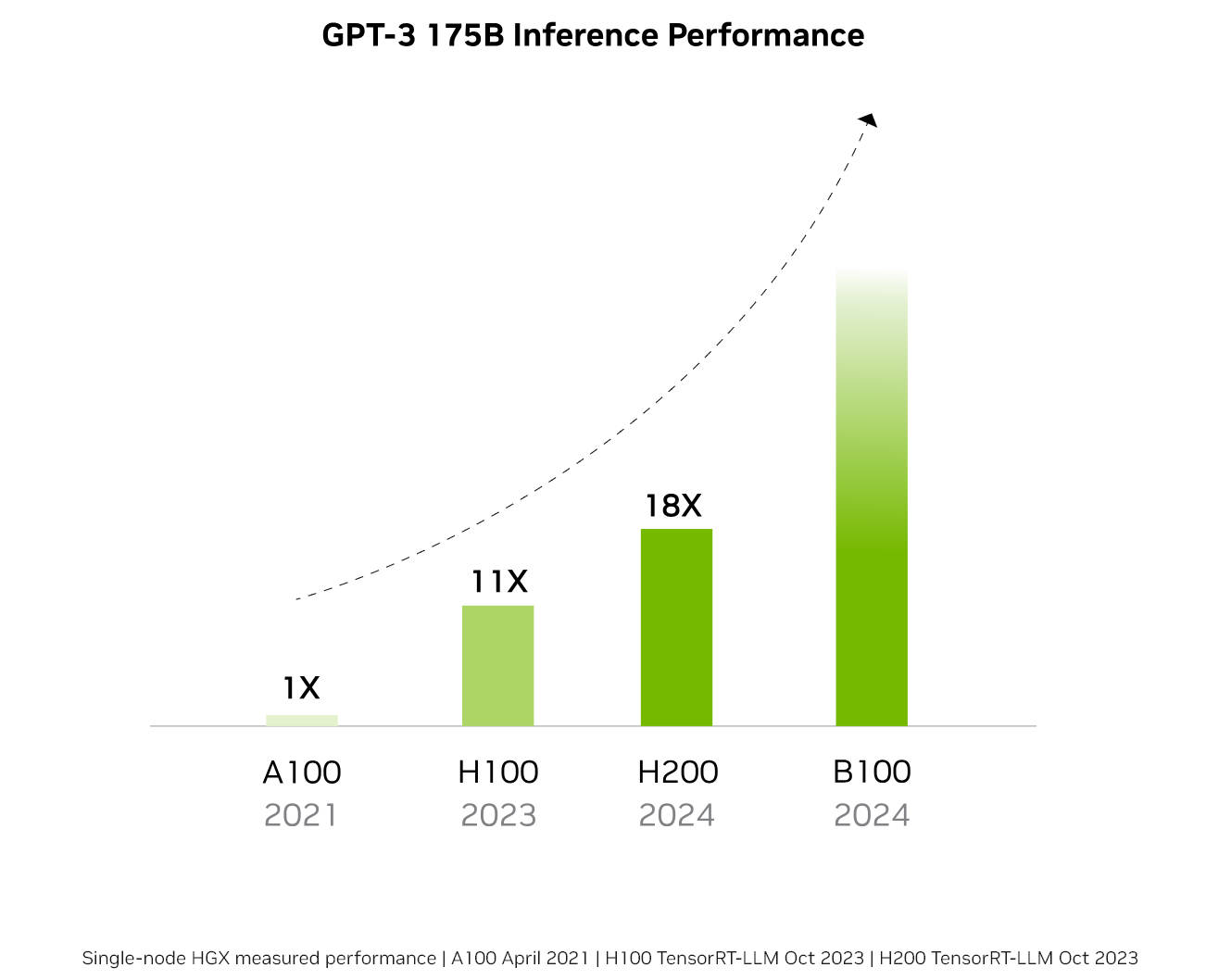
单卡性能方面,H200相比H100,在Llama2的130亿参数训练中速度提升40%,在GPT-3的1750亿参数训练中提升60%,在Llama2的700亿参数训练中提升90%。

在降低能耗、减少成本方面,H200的TCO(总拥有成本)达到了新水平,最高可降低一半的能耗。
英伟达表示,从2021年推出的A100开始,AI芯片的性能每年都有显著提升,预计采用全新架构的B100 GPU将同样于2024年发布,人工智能算力相比H100、H200有望实现倍增。
英伟达HGX H200 AI服务器
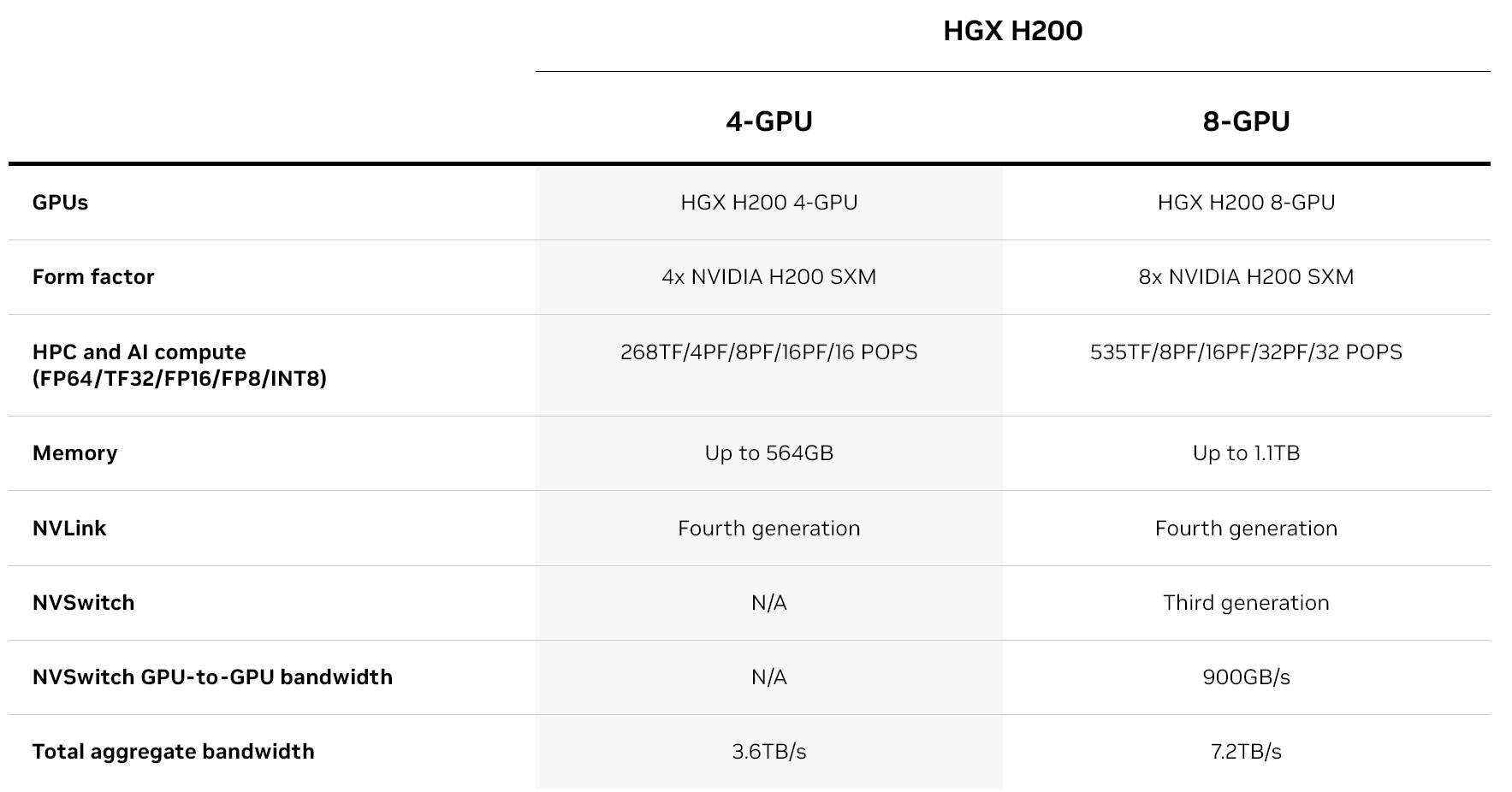
英伟达同时推出了搭载H200 GPU的HGX人工智能服务器系统。该平台提供4-GPU、8-GPU选项,分别具备564GB、1.1TB显存,可满足超大规模AI大模型推理、深度学习计算需求。HGX服务器可配备400Gb/s高速网络连接选项,利用NVIDIA Quantum-2 InfiniBand和Spectrum-X以太网实现互联。此外,NVIDIA BlueField-3 DPU单元,可以在超大规模AI云数据中心中实现云端网络、融合存储、零信任安全性以及GPU计算的弹性。
以下为HGX H200参数:
(校对/孙乐)








