

近日,我组联合面壁智能等机构的研究人员,共同发布了测评大模型 debug 能力的数据集 DebugBench。这一数据集解决了大模型 debug 领域测评数据稀缺的问题、弥补了现有测试集泄漏风险大、规模小、种类单一的缺陷,为衡量模型 debug 能力提供了更可靠的定量指标。其对于热门大模型的测试结果,揭示了开闭源模型之间的能力差距、不同种类 bug 在不同情景下的修复难度差异,以及 debug 任务和 coding 任务之间的关联性。
研究背景
前有 GPT-4 在 HumanEval 和 MBPP 等测评集上超越人类,后有 GitHub Copilot 和 Tabline 成为大小程序员的贴身伴侣,大语言模型写代码的能力正突飞猛进。然而,熟悉编程的人都知道,和写代码(coding)比起来,修复代码错误(debugging)更让人头疼。正如 O'REILLY 系列编程宝典所言,平均来说,debugging 占据了开发时间的 35% - 50%,消耗了项目资金的 50% - 75%。如果大模型在掌握 coding 能力的同时,也能熟练地 debug,那么软件开发的效率将大大提高。
然而,大模型 debug 的研究正面临阻碍。不像 coding 任务有浩如烟海的数据集,能用来评估大模型 debug 能力现状的测评集屈指可数。最近几个月,关于 debug 的研究还在用 7 年甚至 10 年前的数据集。这些测评集存在数据泄漏风险大、规模小、种类单一的局限性,已经无法满足目前 debug 领域的研究需求。

其他测评工作的局限性
为了解决以上问题,我组推出 DebugBench 测评集。DebugBench 由 C++、Java、Python 三种流行编程语言的 4253 个例子组成,涵盖了语法错误、引用错误、逻辑错误和多重错误 4 个大类和 18 个小类的 bug。这些数据来自 LeetCode 用户社区的最新提交结果,利用 GPT-4 完成不同种类 bug 的植入,保证了每种 bug 分类的数据规模,规避了数据泄漏的风险。
数据集构建
DebugBench 数据集的构建可以分为三个部分。
➤ 原始数据收集
首先,研究团队从 LeetCode 平台上收集了 3,206 份用户提交的正确解答。选择 LeetCode 作为数据源的原因主要有两个。一方面,LeetCode 的代码复杂度分布足够广,从答案呼之欲出的 “easy级”,到人看了抓耳挠腮、GPT看了一筹莫展的 “hard级” 应有尽有。另一方面,LeetCode 上的所有代码都有着得天独厚的完备测例集,能够自动、可靠地对模型 debug 的输出结果进行测评,这 GitHub 和其他数据源都望尘莫及。
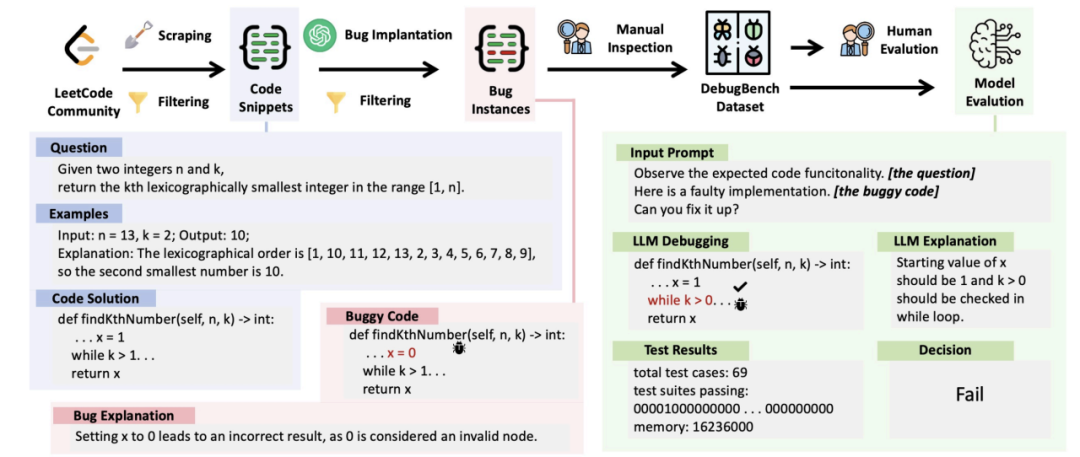
数据集构建过程与数据示例
➤ bug植入
在得到了不同问题的正确解答之后,研究团队使用 GPT-4,根据 Barr 在 Debug 宝书 “Find the Bug: A Book of Incorrect Programs” 中的 bug 分类理念,对正确解答的代码片段进行了 bug 植入。这种获取bug数据的方式不会受到数据源的限制,能够为每个种类的 bug 都提供充足的例子。

用于 GPT-4 bug 植入的提示文本
➤ 质量控制
在构建 DebugBench 的过程中,研究团队观察到了 LeetCode 数据中的噪声和 GPT-4 在植入 bug 中的意外行为。为了排除这些因素的干扰,保证数据集的质量,研究团队在构建 DebugBench 的过程中,对数据进行了多次过滤和人工检查。研究团队通过多次制定过滤规则,保证了原始解答代码的完整性、正确性和时效性,以及 GPT-4 bug 植入的有效性与合理性。最后的人工检查表明,DebugBench 具有较高的数据质量。

人工检查合格率结果
测评实验
➤ Debug能力测评
在得到了 DebugBench 测评集之后,研究团队对 GPT-3.5-turbo-0613、GPT-4-0613两种商用模型和BLOOM、CodeLlama-34b、CodeLlama-34b-Instruct 三种开源模型进行了测评,并将他们的 debug 能力与人类水平进行比较。
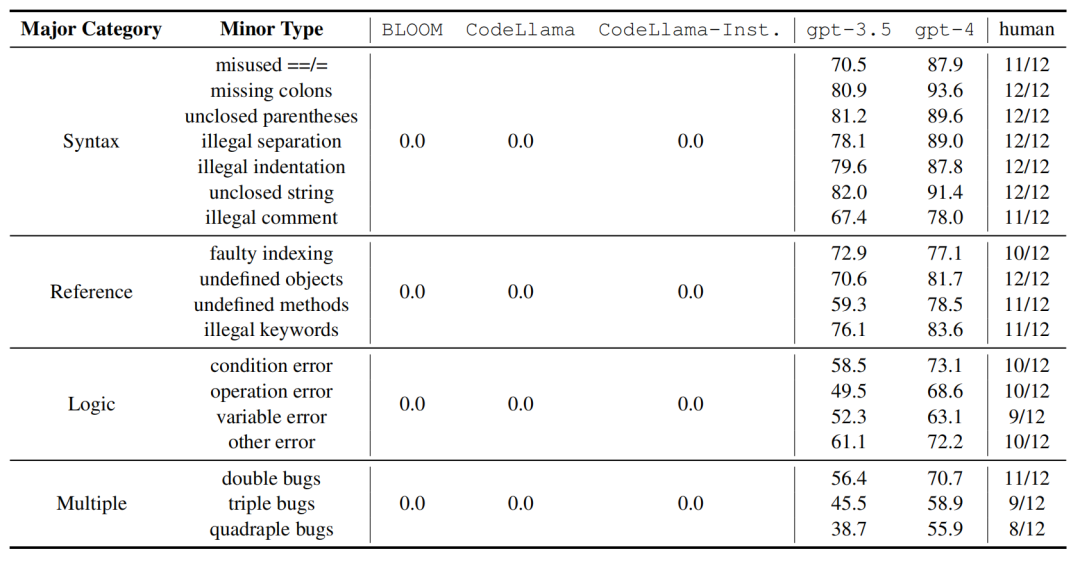
不同模型对于不同种类 bug 的修复成功率
实验结果表明,在 DebugBench 上,GPT-4 和 GPT-3.5-turbo 分别获得了 75.0% 和 62.1% 的 debug 成功率,这和人类的 debug 表现相比稍逊一筹。
同时,三个开源模型的表现都逊色得令人惊讶,debug 成功率都是 0。尽管它们对写代码的能力有相当程度的掌握,但在 debug 方面却一筹莫展,无法输出任何有效的 debug 结果。这可能是因为开源模型在预训练阶段对 debug 类型的输入接触较少,也不能根据指令将写代码的能力泛化到 debug 上。

开源模型对于 debug 任务的输出示例
此外,对于闭源模型来说,修复逻辑类型(logic)和复合类型(multiple,一段代码中有多个bug)错误的难度明显大于修复语法错误(syntax)和引用错误(Reference)。这意味着,在训练debug模型时,需要着重强化它们在处理逻辑错误和复合错误的能力。
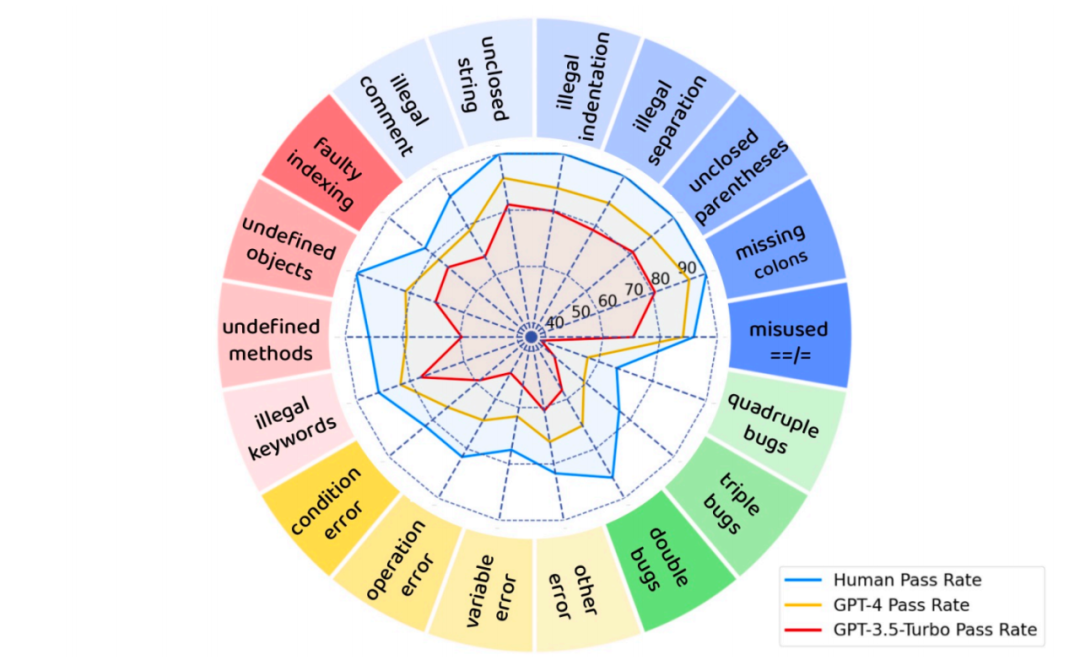
GPT-4,GPT-3.5 和人类对于不同种类 bug 的修复成功率
另一个值得一提的结果是,虽然 GPT-4 和 GPT-3.5-turbo debug 的效果不及人类水平,但是它们的 debug 速度远快于人类。人类程序员 debug 需要经过理解代码含义、编写测例、断点调试等多个步骤,处理 DebugBench 中的每个例子平均需要 20 分钟。但大模型只需要不到十秒钟就能修复一份有 bug 的代码。从这个角度来说,大模型能以极低的时间成本生成一份 debug 结果供人参考,在提升程序员 debug 效率方面已经大有可为了。
➤ Debug 任务和 Coding 任务的比较
最后,研究团队还比较了修复问题代码(debugging)和写代码(coding)的难度差异与相关性。
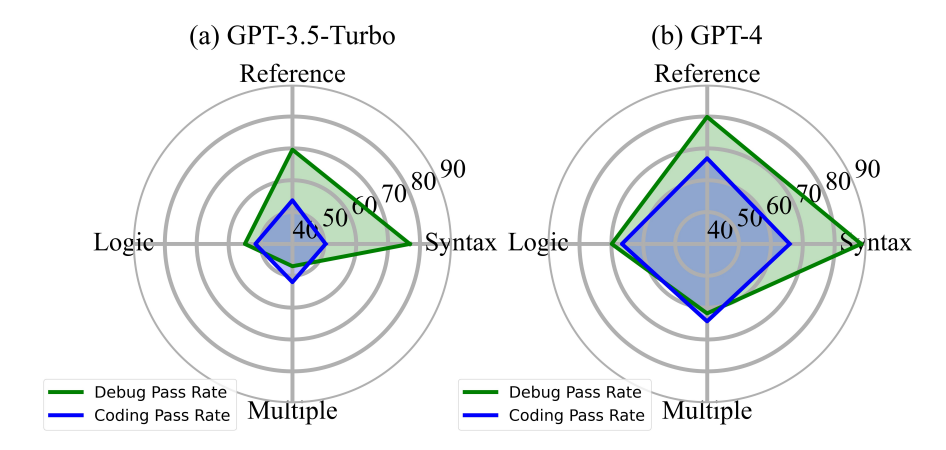
GPT-4 和 GPT-3.5 debugging 和 coding 成功率比较
对于同一个问题,研究团队比较了 GPT-4 和 GPT-3.5-turbo 写代码和修复问题代码的成功率,发现修复语法错误和引用错误的难度明显低于写代码,而修复逻辑错误的难度则与写代码相仿,修复多重错误甚至比写代码更难。
研究团队还通过分析 Phi 系数比较了 debugging 和 coding 两个任务的相关性,发现两个模型对于各种类型的 bug,debugging 和 coding 的 Phi 系数都在 0.1 至 0.3 之间。这意味着对于 GPT-4 和 GPT-3.5-turbo 来说,debugging 和 coding 两个任务所需的能力之间存在正向的关联。
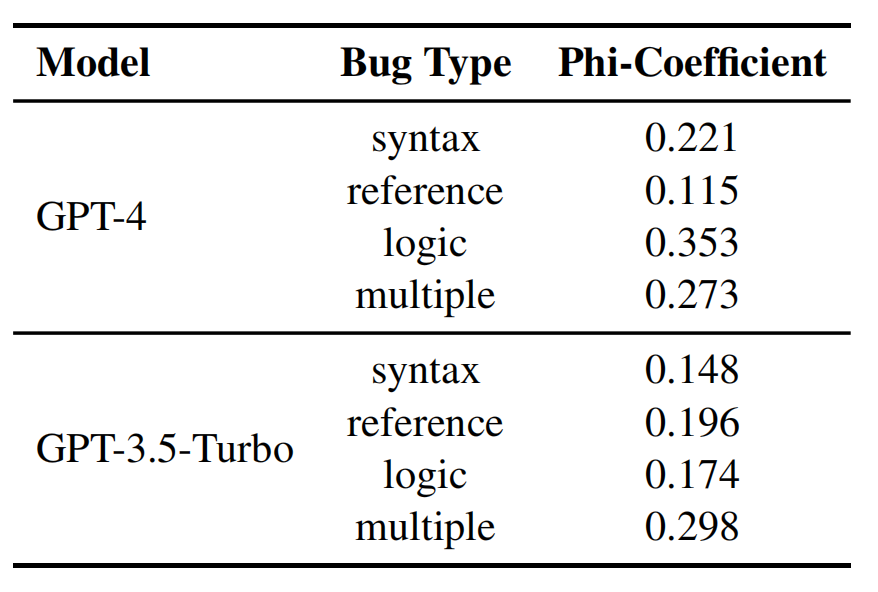
GPT-4 和 GPT-3.5 debugging 和 coding 的 Phi 系数
结论
在这篇工作中,研究团队构建了 DebugBench 数据集,解决了大语言模型 debug 领域测评集稀缺的问题,为衡量大模型debug 能力提供了可靠的指标。同时,研究团队对于常见大模型 debug 能力的测试表明,GPT-3.5-turbo 和 GPT-4 等闭源模型的 debug 能力比人类水平略逊一筹,而 CodeLlama-34b 等开源模型无法生成有效的debug结果。同时,逻辑错误和多重错误的修复难度显著高于语法错误与引用错误,应对这两类错误将是未来增强模型 debug 能力的重点。作为拓展,研究团队还揭示了 debugging 与 coding 能力之间的关联性以及两者的难度差异。这些结论将有利于未来具有更强 debugging 能力和总体编程能力的语言模型的开发。









