
生成式人工智能拉开了全球大算力时代的序幕,而随着众多云计算厂商、大模型厂商等在AI算力基础设施上投入巨资,AI处理器需求急速攀升。作为其中关键器件之一的HBM(高带宽内存)需求也一路看涨,在存储芯片持续低迷的背景下,带动HBM价格逆势激增。在“算力”需求催生“存力”风口的机遇下,纵观整个HBM产业链,能入局的本土企业屈指可数,面对的技术挑战巨大但前景广阔,无论从自主可控角度还是市场竞争角度,均需加快追赶脚步。
HBM需求逆势增长,巨头三分天下
“内存墙”是当前制约高性能计算性能的关键瓶颈,从存储器到处理器,数据传输会面临带宽和功耗的问题,HBM属于图形DDR内存的一种,通过使用先进封装(如TSV硅通孔、微凸块)将多个DRAM芯片进行堆叠,并与GPU一同进行封装,形成大容量、高带宽的DDR组合阵列。HBM通过与处理器相同的硅中介层(Interposer)与逻辑芯片实现紧凑连接,既节省了芯片面积,又显著减少了数据传输时间,从而减少内存和存储解决方案带来的延迟,因而被认为是提升AI处理器性能的关键。
2014年首款硅通孔HBM产品问世,但是自2023年ChatGPT发布以来,AI服务器的强劲需求才推动HBM技术按照HBM第1代(HBM)-第2代(HBM2)-第3代(HBM2E)-第4代(HBM3)-第5代(HBM3E)的顺序快速迭代,第4代HBM3已规模量产并应用,带宽、堆叠高度、容量、I/O速率等较初代均有多倍提升。当前,HBM只有SK海力士、三星电子和美光三大存储巨头能够量产,因而市场呈现“三分天下”的局面,分别占据了53%、38%和9%(TrendForce,2022年)的市场份额。
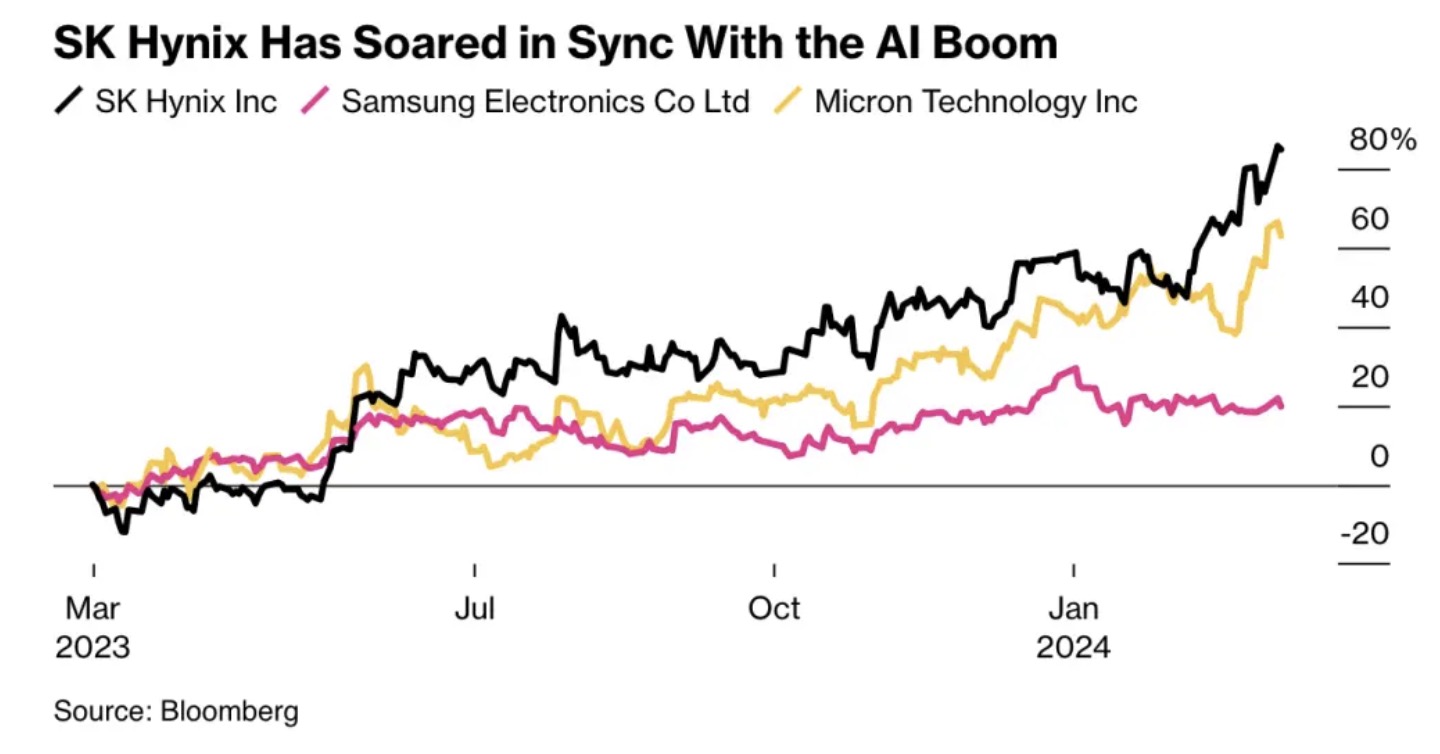
在2023年,市场中主要应用的是HBM2、HBM2E和HBM3,下半年在英伟达H100和AMD MI300的推动下,HBM3渗透率提升。据悉,今年SK海力士完成了8层HBM3E的验证,将于3月份开始批量生产,同时展示了更新的16层HBM3E;三星电子则表示,已经完成了12层HBM3E的开发并将于今年上半年量产,这是迄今为止容量最高的HBM产品。美光也在2024年2月底首次宣布量产8层HBM3E产品。不难看出,SK海力士由于发力更早,在HBM领域取得了先机,并因成为英伟达HBM主力供应商而市值大涨;美光进场最晚,但后来居上,直接从HBM3E下手,对SK海力士和三星电子构成了挑战。
受市场需求推动,SK海力士、三星和美光科技等大厂正纷纷加大产能扩张力度。SK海力士在2月份就透露今年旗下HBM已全部售罄,为了保持市场领先地位,已开始为2025年预作准备。三星则表示,为争夺2024年的HBM市场,计划在今年第四季度之前,将HBM的最高产量提升至每月15万件—17万件。此前,三星还投资105亿韩元收购了位于韩国天安市的三星显示工厂及设备,旨在扩大HBM产能。美光科技CEO Sanjay Mehrotra日前也对外透露,美光科技2024年的HBM产能预计已全部售罄。

尽管三大HBM供应商仍聚焦于迭代HBM3E,单颗DRAM裸芯和堆叠层数仍有提升空间,不过HBM4的研发均已提上日程。Trendforce预计HBM最底层的Logic die(Base die) 将采用12nm制程,由晶圆代工厂提供,使得单颗HBM需要晶圆代工厂与存储器厂来合作。而据媒体报道,SK海力士正在招募CPU、GPU等逻辑芯片的设计人员,目标是将未来的HBM4以3D堆叠的形式直接堆叠在英伟达、AMD等公司的逻辑芯片上,预计该HBM4内存堆栈将采用2048位接口。但该方案未定,只是在讨论中。
HBM量价持续飙升,国产供应链迎头赶上
由于HBM使用的芯片比标准DRAM大两倍以上,意味着生产相同体积的芯片需要两倍以上的容量,这也促使DRAM从传统2D加速走向立体3D,从而突破了内存容量与带宽瓶颈,成为新一代的DRAM技术路线之一。
从HBM器件结构来看,其主要特点在于,首先,3D堆叠结构,并由TSV互连。HBM由多颗DRAM裸芯堆叠成3D结构,并通过TSV工艺实现信号的共享和分配;其次,高I/O数量带来高位宽。HBM的每颗DRAM裸芯均包含多个通道,可独立访问,每个通道又包含多个I/O口,使得总位宽大大提高。这样的器件结构,得以实现存储密度更大、功耗更低、带宽更高的优势。通过CoWoS封装将HBM与逻辑计算核心互连,成为GPU、FPGA、CPU等高性能计算芯片的首选。
随着AI、机器学习等技术的快速发展对高速、大容量存储需求急剧攀升,HBM已然成为当前存储市场最为炙手可热的领域。Yole预测,2024年HBM市场将达到141亿美元,2029年则将达到380亿美元。2023至2028年HBM供应的年均复合增长率将达到45%,由于难以扩大生产,HBM的价格预计将长期保持在较高水平。
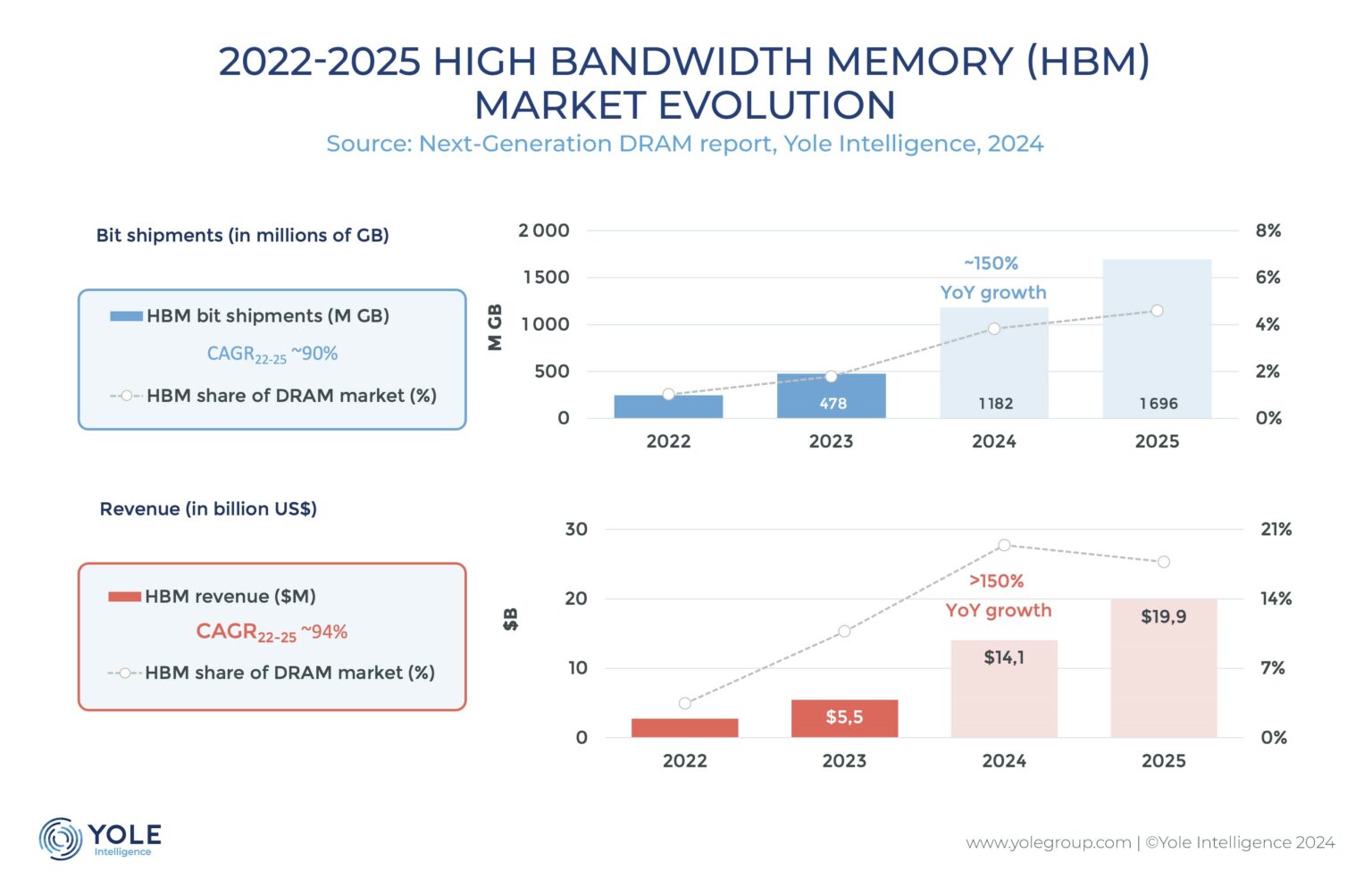
在巨大的市场蛋糕面前,除了三巨头持续加大研发量产力度,一些二线、三线DRAM厂商也开始切入HBM赛道,而国产厂商随着国产AI处理器的水平提升,对配套的自主HBM供应链需求也越发紧迫。
例如中国台湾的华邦电于去年8月介绍了其类HBM高带宽产品CUBEx, 采用1~4层TSV DRAM堆叠,I/O速度500M~2Gbps,总带宽最高可达1024GB/s,颗粒容量为0.5~4GB,功耗低至不足1pJ/bit。这种比常规HBM拥有更高带宽的CUBEx可用于AR、VR、可穿戴等领域。
大陆方面,目前国际一线厂商DRAM制程在1alpha、1beta水平,国产DRAM制程在 25~17nm水平,中国台湾DRAM制程在25~19nm水平。国内DRAM制程接近海外,且国内拥有先进封装技术资源和GPU客户资源,有强烈的国产化诉求,未来国产DRAM厂商有望突破HBM。
近日就有媒体爆出,某国内存储龙头启动HBM项目,正寻求增加设备。封测龙头长电科技在投资者互动中表示,其XDFOI高密度扇出封装解决方案也同样适用于HBM的Chip to Wafer 和Chip to Chip TSV堆叠应用;通富微电此前表示,南通通富工厂先进封装生产线建成后,公司将成为国内最先进的2.5D/3D先进封装研发及量产基地,实现国内在HBM(高带宽内存)高性能封装技术领域的突破,对于国家在集成电路封测领域突破“卡脖子”技术具有重要意义。
值得一提的是,HBM的研发、制造涉及复杂的工艺和技术难题,包括晶圆级封装、测试技术、设计兼容性等。CoWoS为目前主流的AI处理器封装方案,包括其中集成的HBM也采用了该封装技术。CoWoS(以及HBM)涉及到的工艺包含TSV、Bumps、microBumps、RDL(重布线)等。其中又以TSV在HBM的3D封装成本中占比最高,接近30%。以4层DRAM存储芯片与一层逻辑芯片堆叠为例,在99.5%的键合良率下,TSV创建和TSV显露分别占总成本的18%和12%;在99%键合良率下,分别占总成本17%和11%,是HBM工艺中价值量占比最高的部分。TSV的良率水平反映了制造过程中出现缺陷的机会,如果HBM中的一层被证明有缺陷,那么整个堆叠都会被丢弃,因而造成整体良率难以提升。
日前海外分析师表示,三星HBM3芯片的生产良率约为10%~20%,而SK海力士的HBM3良率可达60%~70%。最大的原因就在于三星坚持使用热压非导电薄膜(TC NCF)制造技术,这会导致一些生产问题。而SK海力士则大规模采用回流模制底部填充(MR-MUF)技术,可以克服NCF的弱点。
此外,堆叠键合是HBM制程中的核心技术,会影响到芯片的良率以及散热性能,也是HBM器件制造的关键工艺。
大陆目前只有长电科技、通富微电和盛合晶微等一线封装厂商拥有支持HBM生产的技术(如TSV硅通孔)和设备。在其余供应链上,芯片设计企业国芯科技则表示已与合作伙伴一起正在基于先进工艺开展流片验证相关chiplet芯片高性能互联IP技术工作,和上下游合作厂家积极开展包括HBM技术在内的高端芯片封装合作。紫光国微表示,公司HBM产品为公司特种集成电路产品,目前还在研发阶段。香农芯创此前表示,公司作为SK海力士分销商之一具有HBM代理资质。公司未来根据下游客户需求,在原厂供应有保障的前提下形成相应销售。飞凯材料表示,环氧塑封料是HBM存储芯片制造技术所需要的材料之一,MUF材料按性状和工艺分不同品种,目前公司MUF材料产品包括液体封装材料LMC及GMC颗粒封装料,液体封装材料LMC已经量产并形成少量销售,颗粒填充封装料GMC尚处于研发送样阶段。兴森科技表示,公司的FCBGA封装基板可用于HBM存储的封装,但目前尚未进入海外HBM龙头产业链。
尽管如此,能真正入局HBM产业链的中国企业仍是屈指可数且大多集中于上游材料端,由于GPU遭遇国际管制,无论从国产自主角度还是市场竞争角度,国产AI处理器的突破迫在眉睫,HBM的同步突围也需不能落后太多。









