


生成式AI时代正催生着对于移动处理器性能和能耗的更多要求。在近日2024台北电脑展举办前夕,Arm正式推出全新一代面向智能手机、PC等终端的平台型解决方案-Arm终端计算子系统(CSS),凭借面向3nm节点的工艺优化,最新Armv9架构加持,显著提升性能和能效,重新定义移动端体验。Arm终端CSS解决方案,将助力于芯片厂商加快产品上市,提升工程效率和降低成本,为终端AI的发展注入创新活力。
在日前举办的媒体沟通会上,集微网同Arm方面进行了交流,Arm方面就产品的创新性,架构创新,产业协同等方面进行了深入的分享。
IPC性能暴涨近4成 同比增幅最高
Arm终端CSS是迄今速度最快的Arm计算平台,其具备最新的Armv9.2CPU、Arm Immortalis GPU、基于3纳米工艺生产就绪的CPU和GPU物理实现。
从内部的参考平台具体来看,在CPU方面,包括2个全新的超大核心Cortex-X925,4个高性能核心Cortex-A725和2个能效核心Cortex-A520,最多支持14个CPU内核。

相较于以往“Cortex-X+个位数”的命名方式,本次Arm发布的超大核心命名为Cortex-X925。Arm方面的解释称为了凸显Cortex-X925性能和能效上的跨越。作为Cortex-X系列发布以来IPC同比增幅最高的超高性能核心,3.8GHz的时钟频率和最大缓存大小的条件下,与 2023年旗舰智能手机的四纳米 SoC 相比,Cortex-X925在单线程性能上提高36%,在AI性能表现上提升41%,显著提高如大语言模型等终端设备生成式AI的响应能力。
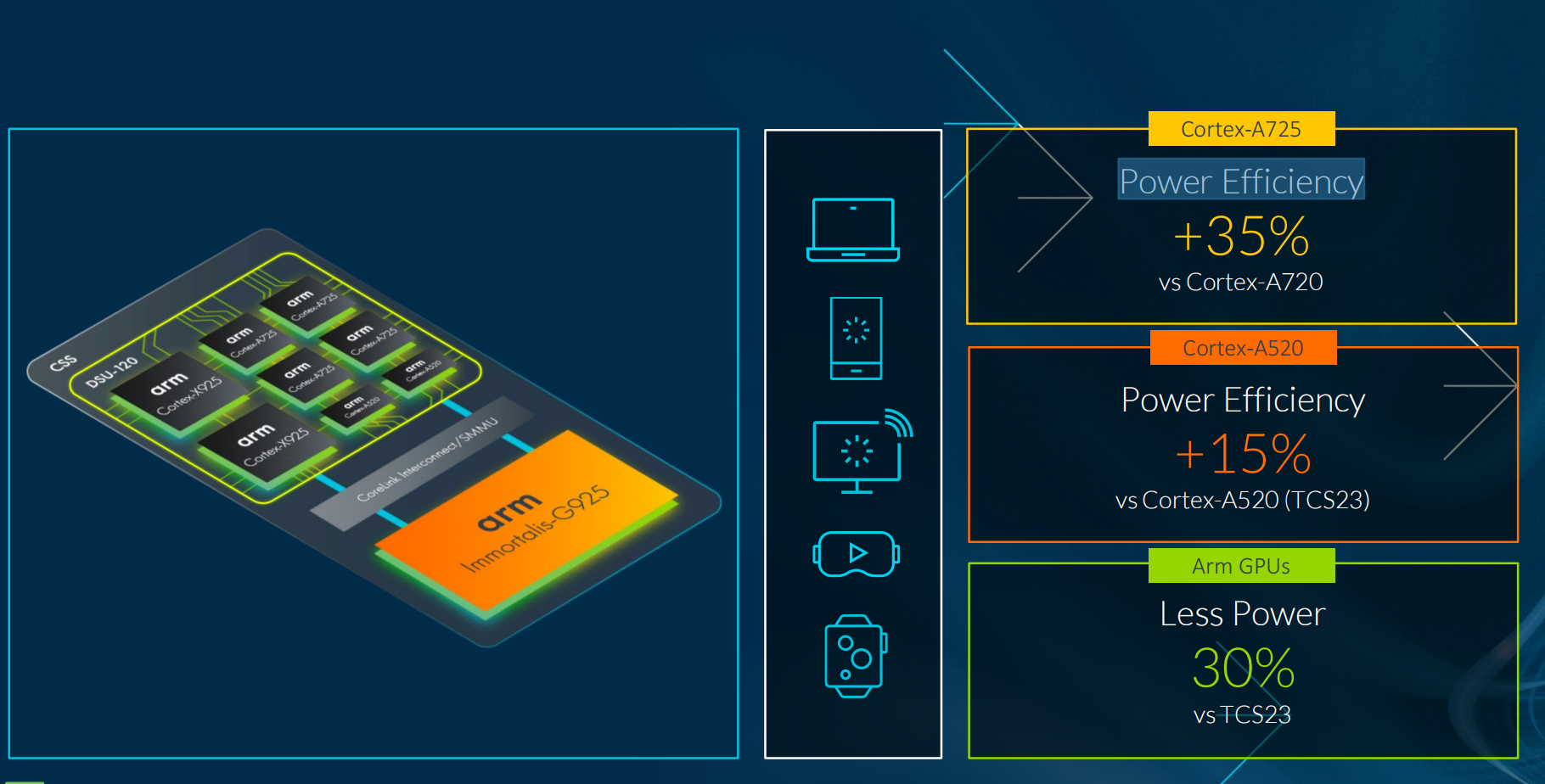
能效表现上,得益于先进工艺节点和微架构上的改善,相比上一代产品,Cortex-A725提高35%,Cortex-A520提高15%。
在GPU方面,最新一代产品命名也直接从Immortalis-G720跃升到Immortalis-G925,成为Arm有史以来发布的最强GPU产品,在多款领先的手游应用的图形测试中,实现了37%的性能提升,且在提供与去年终端平台相同水平的游戏性能下,《堡垒之夜》等手游的功耗降低了30%。

作为Arm推出的第三代具备光追技术的GPU,在面对复杂物体时,Immortalis-G925实现了光追性能52%的提升。通过与Epic Games等游戏巨头的合作,使得大型桌面主机游戏能够在Arm GPU上高效运行。同时,Arm此次也同步推出了新的Mali-G725 GPU与Mali-G625 GPU,借此对应更多不同处理器设计。
Arm全新一代的旗舰产品在性能和能效方面的跃升,得益于微架构上的显著演进。而不同种类的CPU微架构,也使得其具备更高的可扩展性,支持从智能手机、笔记本电脑、数字电视以及可穿戴设备等更多的设备形态。
据Arm方面介绍,Cortex-X925通过采用迄今为止最宽的解码和矢量设计,实现了50%TOPS数的增长。通过更强的可配置性和更大(3MB)的私有L2缓存“大小核”架构,保留进出过CPU的指令和数据。
DSU 120作为协调处理器核心和缓存的关键组件,在今年的更新中,引入了L3快速休眠模式,此功能可确保L3缓存在不使用时进入低功耗状态,并根据需要自动唤醒。在CPU和GPU之间,通过最新的CoreLink™ 系统互连和系统内存管理单元 (SMMU)连接,并优化到内存及SoC其他部分的计算路径。
此外,通过基于最新的Armv9.2架构,显著增强了再矢量加速、机器学习等AI方面的计算能力,以及系统的安全性和稳健性,同时针对3nm工艺进行的优化,使其能够大幅减少延迟,降低功耗并提高性能。
终端CSS:加快产品落地
2021年,Arm首次推出全面计算解决方案(TCS)。简单而言,TCS希望从系统化、协同化的视角打造SoC。包括开发用于总线互联、系统级缓存(SLC)和内存管理单元(MMU)的第三方系统IP,以及将所有组件集成到CPU和GPU集群等各个环节中遇到的问题,从而大幅降低SoC设计的复杂性,从而减少工程成本和资源消耗,缩短产品上市时间。
CSS(计算子系统)方案此前曾在Arm数据中心Neoverse上实施,此次Arm将其引入消费类产品,在TCS的基础上更进一步,首次在终端领域以CPU和GPU整合优化的设计形式提供物理实现解决方案。
据Arm终端事业部产品管理副总裁James McNiven介绍,Arm的大多数的IP是通过RTL,以软件形式进行交付,主要涉及对IP产品的描述。而要使RTL成为芯片还需要通过EDA工具流,才能将这套描述转变成实际的芯片布局(晶体管和线路等)。“物理实现”意味着Arm在提供的方案中已经完成了这些工具流。
上述过程涉及到预先整合IP和EDA工具、设计服务、代工资源以软件库、开发工具等。
“RTL形式的IP交付依然存在,我们只是额外提供合作伙伴物理实现形式的选项,毕竟要把 RTL转变为物理实现需要花费一定的时间,并且需要基于对产品的全盘了解做出决策。而通过提供物理实现,我们可以帮助合作伙伴节省时间,也有助于他们实现更佳的性能和效率。”James McNiven强调。
先进制程的演进为半导体制造带来了许多机遇和挑战。对于很多前端设计者而言,在高性能和低功耗的芯片设计中,由于物理设计上的很多限制,不同的代工厂商的工艺特点,很多初版RTL设计都无法达到理想的PPA,不得不经过和综合、后端设计的沟通来多次迭代和修改设计才最终达成目标。
而Arm终端CSS方案,从系统的视角全面看待RTL和物理实施共同开发,针对“目标节点”,直接给出了能够用于台积电或三星等代工厂用于生产的GDSII,相当于把IP选择、系统配置、布局规划、验证、确认、第三方IP和晶圆厂集成等繁琐的流程和开发步骤统统精简掉,为客户进行优化改进,合作伙伴得以轻装上阵,确保芯片设计厂商的计算IP能够满足性能预期,同时又能克服先进工艺技术带来的挑战,从而专注于根据自身需要开发差异化的高性能低功耗处理器产品,由此大幅缩短产品上市时间,同时显著降低工程成本。
Arm Kleidi:助力应用开发
帮助开发者获得打造创新AI 应用所需的性能、工具和软件库在优化人工智能(AI)和基于计算机的应用程序方面发挥着至关重要的作用。这些库为开发人员提供了量身定制的工具,以最大限度地提高Arm最新内核的性能和效率。
为充分利用Arm终端CSS的性能优势和潜力,针对开发者,Arm同时推出了量身定制的工具和软件库,从而助力开发者和生态能够实现创新。
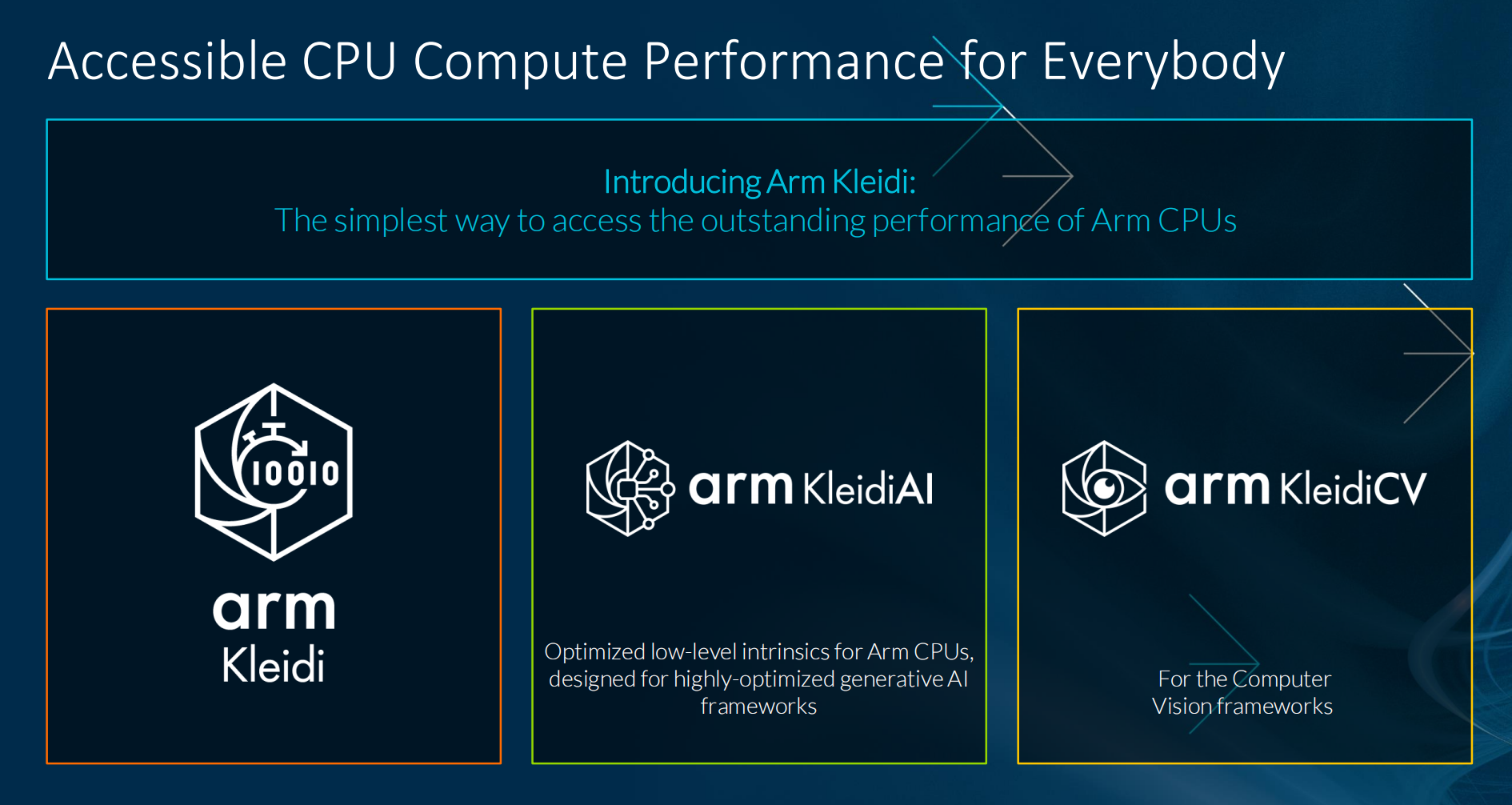
其中,Arm Kleidi包括面向 AI 工作负载的 KleidiAI 和面向计算机视觉应用的 KleidiCV。KleidiAI 是一套面向 AI 框架开发者的计算内核,使他们能够在各种设备上轻松获得 Arm CPU 上的最佳性能,并支持 Neon、SVE2 和 SME2 等关键 Arm 架构功能。KleidiAI 与 PyTorch、Tensorflow、MediaPipe 等热门 AI 框架集成,旨在加速 Meta Llama 3、Phi-3 等关键模型的性能,并且还可前后兼容,以确保 Arm 在引入更多技术时依然能适用未来市场的需求。
据 James McNiven介绍,能出色且应用普遍的Arm CPU是在安卓设备上运行AI的首要目标,当前,有70%的第三方安卓ML工作负载都在CPU上运行。而Keidi 能够确保开发者可从 Arm 终端 CSS 中最新的 Armv9 功能中获得最佳性能,例如可伸缩矢量扩展 (Scalable Vector Extensions, SVE)。而且在Arm已推出的 CPU 核心上,同样能够出色运行,与此同时,它也为未来的 CPU 创新做好了准备,例如可伸缩矩阵扩展 (Scalable Matrix Extensions, SME)。
“当运行于Cortex-X925上时,Kleidi技术运行最新Llama 3和Phi-3 LLM的速度要比参考实现快2.9倍,而且只用不到24小时就能实现。从根本上讲,计算机视觉现在与AI紧密相连,但这些摄像头管线可不仅仅运行神经网络,还有很多传统的计算机视觉算法,其性能对于摄像头或社交媒体应用的顺畅运行至关重要。这就是我们构建 KleidiCV的原因。当我们将KleidiCV融入到常用的 OpenCV 库时,性能便有了显著改进。今年,我们还与 OpenCV.ai 合作,力求让安卓开发者可以更轻松地将 OpenCV 纳入到他们的项目中,并从 KleidiCV 带来的改进中受益。因此,这对于我们来说是一个非常重要的开始,也期待在未来几个月里能看到更多的软件库、更多的集成和更多的成功案例。” James McNiven表示。
除了Kleidi,Arm还提供了一套强大的开发工具和平台,包括参考软件堆栈和性能优化工具,如Arm Performance Studio,它提供了对应用程序性能的详细见解,并帮助开发人员微调其软件以最大限度地提高效率。
提升应用体验 打造繁荣生态
Arm终端CSS解决方案在性能和效率提升,将带来安卓用户体验在应用体验上的显著改善。
比如,在Cortex-X925带来的30%性能提升基础上,Arm对网页浏览器进行了改进,使其性能提高了23%。游戏运行的每帧能耗降低了25%,帧速率则提高了35%。此外,Arm还通过调整了安卓工作负载在不同CPU核心之间的平衡方式,从而为YouTube节省了高达10%的功耗。针对Google的AV1视频编解码器,Arm通过对其进行了软件优化,使当下安卓设备的视频性能最多可提高40%。

据James McNiven介绍,对于实现如Arm终端CSS的完整解决方案来说,Arm会针对不同用例或某些测试基准,设定目标,并将其分解到单个IP当中。以游戏《原神》为例,Arm先从系统层面进行分析,然后针对GPU、图形性能、CPU等设定提升的目标,将各类游戏机制和计算能力推向极限。每个单一IP的性能提升都为终端CSS的整体性能添砖加瓦,从而带来更好的应用体验。
此外,在当前火热的AI PC领域,Arm也是重要的参与者。基于Arm架构的芯片目前在性能上已经追平甚至超过X86,同时凭借在功耗、续航方面的能力优势, 高通、微软等龙头的推动,Windows on Arm (WoA)生态正在崛起。这或许也是在今日台北电脑展上,Arm的CEO豪言在Windows中的市场份额将超过50%的底气所在。

在James McNiven看来,对于 Windows on Arm (WoA) 生态系统来说,今年也是成果丰硕的一年。除了 Microsoft Office、Dropbox、Zoom、Adobe 套件外,有越来越多的应用成为Arm原生应用,尤其是百度、哔哩哔哩、Chrome 浏览器、爱奇艺、搜狗、腾讯QQ音乐等。还包括许多针对创作者的开源工具,例如最近新增的 Audacity、Blender 和 OBS Studio(用于流媒体),这些应用整合了大量的开源库和开发者工具。
“我们很荣幸能与微软合作,通过资助开源和发布我们面向 Windows 的 Arm Performance Libraries(Arm 性能库)来发展这个生态系统。对于现在的大多数用户来说,他们绝大部分时间都在运行原生应用。”James McNiven说。
James McNiven强调,鉴于很多应用依托于开源库和工具,Arm会继续大力投资于开源项目,进而让这些项目中的应用更易于落地为Arm原生应用。比如,面向 Windows的Arm Performance Libraries(Arm 性能库)与Kleidi有类似之处,面向 Windows 系统优化运算例程,进而使开发者能提升WoA应用的性能。
推动产业协同 加速终端AI创新
作为集成电路产业基石类IP厂商,Arm的创新对于行业发展起到关键的推动作用。但随着日益高涨的高性能计算需求,创新周期进一步压缩,仅靠单一厂商实现对于产业的推动越来越具有挑战,产业链系统创新成为趋势。
Arm终端CSS可以被视为Arm推动下产业链上下游共同创新的果实。其针对3nm节点所强调的物理实现,便是建立在同EDA厂商、代工厂商,以及部门内部共同合作的基础之上。
比如今年2月,三星与宣布扩大与Arm在GAA工艺方面的合作,去年新思宣布加强双方在AI增强型设计方面的合作。此外,还包括与联发科、vivo等芯片和终端厂商的合作。
vivo首席芯片规划专家夏晓菲表示,终端手机厂商一直非常关注用户体验,当前衡量手机性能往往通过基准测试,但其只代表手机部分性能,和实际应用程序对比,会发现具有更高的缓存要求,而处理器的访存能力是影响整个用户体验流畅性以及续航的关键。而过去几年Arm在前端访存能力方面持续投入,包括指令预取、分支预测、更大的cache能力等,使得实际应用的性能实现更大幅度提升。
“去年 vivo X100 的手机上面发布了蓝晶芯片技术栈,和合作伙伴联发科一起探索了全大核架构的使用,这个背后也把Arm在CPU上针对实际应用提升部分的性能充分地发挥出来,这是 Arm 微架构提升带来的价值,最终使我们手机流畅性用户体验方面达到了非常高的水准。”夏晓菲说。
此外,James McNiven表示,针对先进制程节点,Arm同代工伙伴保持密切合作。
“我们会倾听他们对工艺、设计和基础构建方面的反馈意见,并且与之分享Arm使用其工艺的经验,相互学习和借鉴。在帮助合作伙伴提升工艺的同时,他们也帮助我们改进设计。我们的RTL和物理设计团队之间也会展开了进一步协作,针对制程工艺节点,提升频率和效率。”James McNiven说。








