

1 为什么要做私有化模型部署?
首先了解,什么是开源大模型?
开源大模型是基于开放源代码和共享数据集构建的人工智能模型。市场上知名的开源大模型如Meta AI的LLaMA 3.1 405B,Mistral AI的Mistral Large 2,深度求索(deepseek)的DeepSeek-V2等,在自然语言处理、文本生成等领域展现了卓越的性能。这些模型都是开源的,并且在全球范围内被广泛使用和研究。
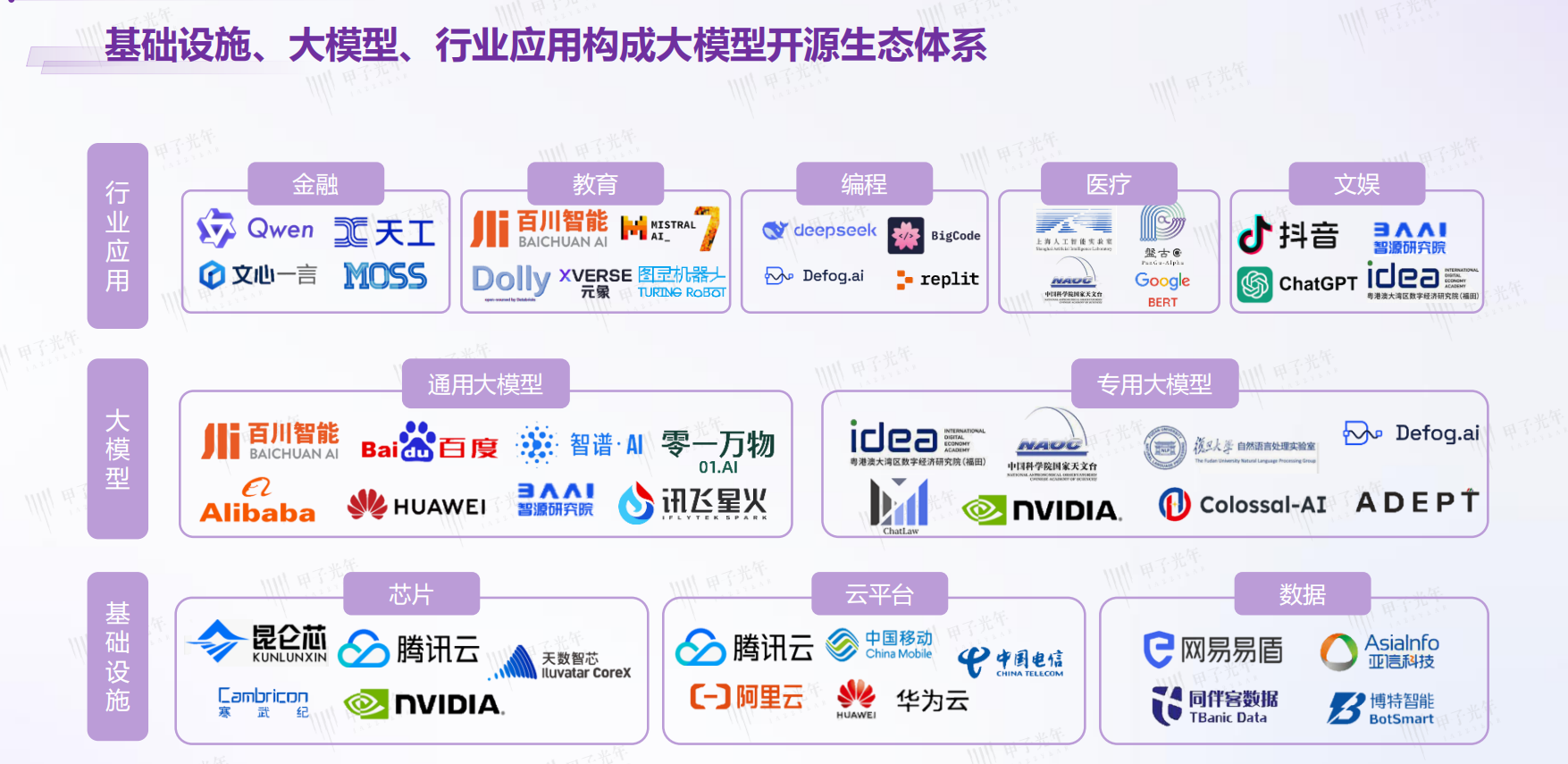
数据来源:甲子光年智库
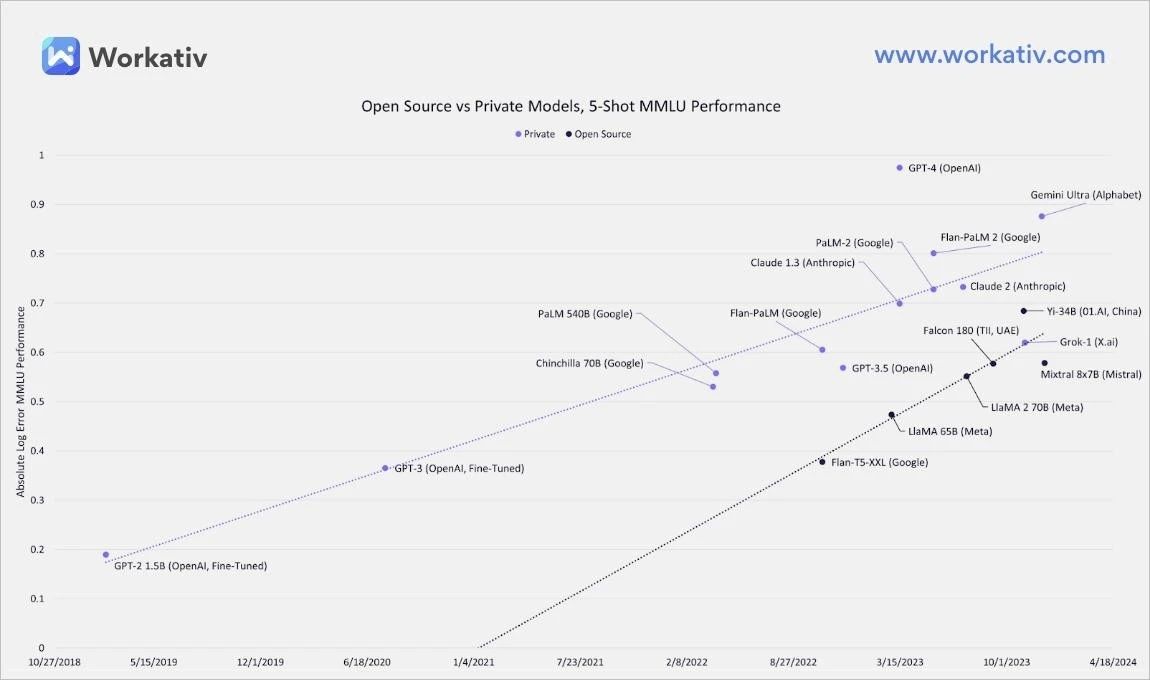
但开源大模型也存在一些挑战和不利因素。首先是隐私和安全问题。开源大模型的训练数据通常来自公开领域可能包含大量的个人信息和敏感数据,这可能引发隐私泄露和滥用的担忧。
另外,开源大模型的通用性可能导致在高阶任务或特定行业上的性能表现不尽如人意。以半导体行业为例,对于如缺陷图像识别、专业技术问答等特定需求较高的任务,开源大模型无法正确理解和处理,就需要进行额外的定制和优化工作。这就开启了开源大模型的定制化之路。
开源大模型从通用到定制化,需要经过模型选择、数据清洗、模型微调对齐、评估验证、优化迭代、部署集成等多个步骤,每一步都对大模型研发团队的技术实力、行业知识和专业精度提出了考验。

模型微调和指令微调
1、模型微调,是连接通用模型与定制化应用的纽带。
它通过在特定任务的数据集上进一步训练预训练模型,使得模型能够更好地适应和执行该任务。这种方法不仅减少了从头开始训练模型所需的时间和资源消耗,而且还能够针对特定的业务需求进行定制化调整,从而提升模型在特定任务/垂直行业上的性能。
众所周知,在OpenAI训练大语言模型GPT-4时,完成一次训练需要约三个月时间,使用大约25000块英伟达A100 GPU,1次训练用电2.4亿度电。每家公司都去从头训练自己的大模型,这件事情的性价比非常低。而使用开源大模型进行模型微调,可降低大模型定制化的门槛,加速AI应用的开发和部署。
模型微调时,需要繁复的数据集准备过程,涵盖了数据收集、清洗、标注、增强、平衡、划分等多个步骤。在这过程中,数据质量尤为关键。它不仅决定了模型训练的起点,更是影响着私有化大模型最终能否达到预期效果。
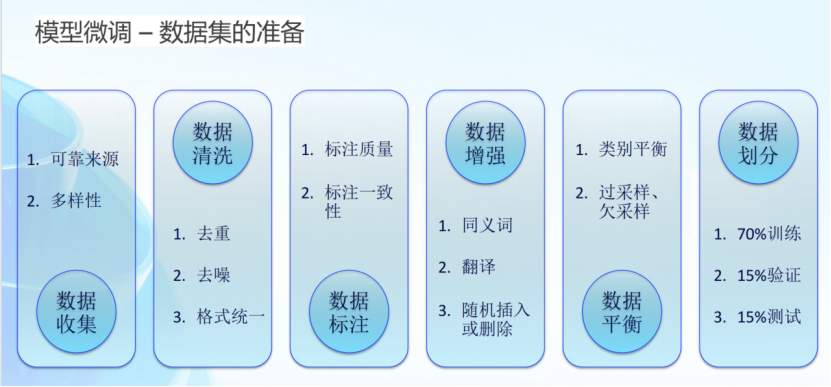
数据质量的优劣,会直接映射在模型的表现上。大量重复的低质量数据可能导致训练过程不稳定,造成模型训练不收敛。训练数据的构建时间、包含噪音或有害信息情况以及数据重复率等因素,都对大语言模型性能存在较大影响。
因此,高质量数据及模型微调水平,是铸就大模型卓越表现之关键。
2、指令微调,是一种更为精细的调整方式。
指令微调又称为监督微调,是模型微调的主要类型之一。
它通过设计特定的指令或提示来引导模型生成或预测所需的输出。这种技术使得模型能够更加灵活地响应用户的指令,提高交互的自然性和准确性。在私有化大模型的应用中,指令微调尤其重要,因为它允许模型在保持预训练知识的同时,还能够理解和执行特定领域的任务,从而实现特定领域的专业化适配。
举个例子
以半导体“晶圆缺陷识别”为例,在微调过程中,使用设计好的指令和对应的图像数据对模型进行微调。模型学习将指令与图像特征(如划痕、凹坑、凸起、裂纹、变形、错位等)关联起来,以提高对特定缺陷的识别能力。
部署私有化大模型的过程,每一项都是壁垒。从“模型选择”到“数据准备、处理”,再到“模型微调与对齐”,直至深入探索应用领域,智现未来不仅积累了丰富的经验,还在国内某头部客户的项目中成功实现了落地,带来了卓越的应用成效。这凸显了智现未来在大模型定制转化的专业实力和创新能力。
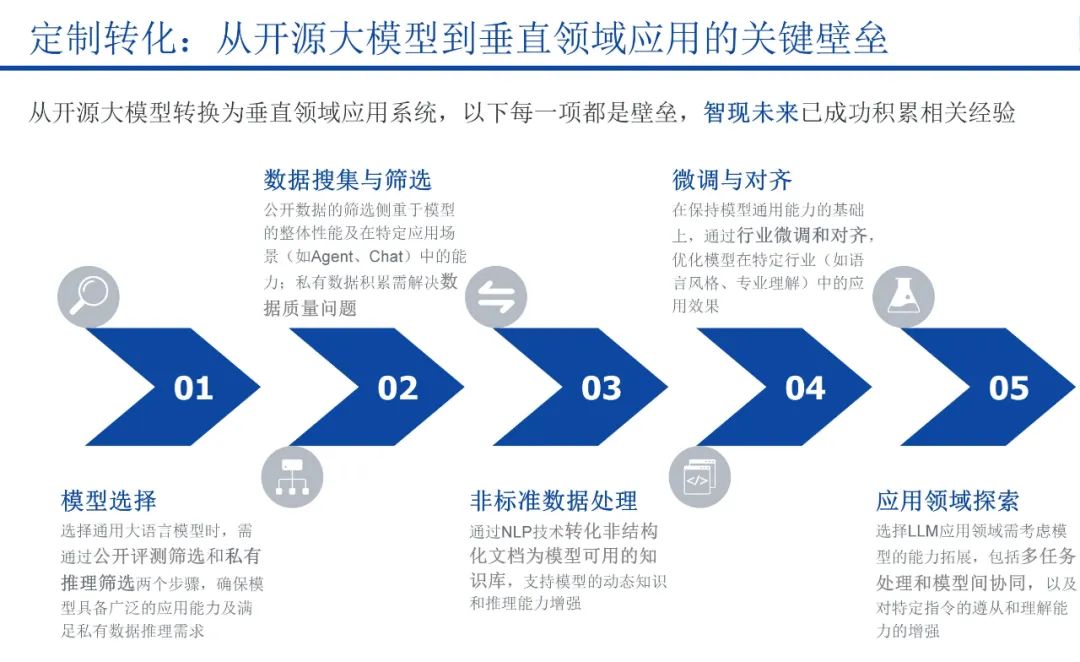
智现未来积累的数据优势铸就了其大模型的数据壁垒,这源于公司对丰富且高质量的行业私有化数据积累、深入的行业知识理解以及高效的数据处理能力。
如智现未来的大模型基础应用"专家问答"系统,则是其数据能力的具体体现。"专家问答"融合了“半导体行业公域数据,智现未来20余年私域数据,以及客户私有数据”等多方数据的微调和对齐,采用先进的多模LLM+RAG检索增强生成架构,增强行业知识应用,有效解决通用大模型幻觉、专业性不强、答非所问等问题。
此外智现未来大模型的卓越表现能力也体现在了晶圆缺陷识别、良率管理预测、智能报表生成、反馈优参等诸多具体“大模型+”应用上。
私有化大模型与工业场景应用需求深度融合,有利于实现更高水平的生产创新。智现未来作为AI智造的深度赋能者,愿与高端制造行业的众多客户紧密合作,解锁更多的生产创新可能,实现工业生产流程的优化和智能化。









