


当代电子计算体系的表现完全依赖于处理器和内存的相互配合,根据冯诺伊曼的设想,两者之间的速度应该非常接近,但摩尔定律让这一美好设想落了空。处理器的性能按照摩尔定律规划的路线不断飙升,内存所使用的DRAM却从工艺演进中获益很少,性能提升速度远慢于处理器速度,造成了DRAM的性能成为制约计算机性能的一个重要瓶颈,即所谓的“内存墙”。
在AI芯片大幅兴起的时代,对内存的要求更是有增无减,业界为了打破内存墙而设计了多种方案,HBM(高带宽存储器 High Bandwidth Memory)就是其中的一种。这种新型的内存方案具备高带宽、低功耗的特点,已逐渐在竞争中脱颖而出,成为AI芯片的重要之选。同时,随着工艺的不断提升,5G等应用也在对其敞开大门。
突破带宽极限
在AI应用当中,内存和I/O带宽是影响系统性能至关重要的因素。如果内存性能跟不上,对指令和数据的搬运(写入和读出)的时间将是处理器运算所消耗时间的几十倍乃至几百倍。换而言之,很多AI芯片所描述的实际算力会因为存储器的因素降低50%甚至90%。
解决这个问题的根本就是采用新型的内存方案,最有代表性的就是GDDR和HBM。GDDR发展自DDR,采用传统的方法将标准PCB和测试的DRAMs与SoC连接在一起,具有较高的带宽和较好的能耗效率,其缺点在于更难保证信号完整性和电源完整性。
HBM同样也基于DRAM技术,使用TSV(硅过孔)技术将数个DRAM芯片堆叠起来,并通过贯通所有芯片层的柱状通道传输信号、指令和电流。
凭借TSV方式,HBM大幅提高了容量和数据传输速率,与传统内存技术相比,HBM具有更高带宽、更多I/O数量、更低功耗、更小尺寸,可应用于高性能计算(HPC)、超级计算机、大型数据中心、AI、云计算等领域。
“HBM的传输速率会容易提升,原因在于采用2.5D的封装,整个信号完整性要比 DDR要更容易实现。”业内资深人士白文杰(化名)这样评价。
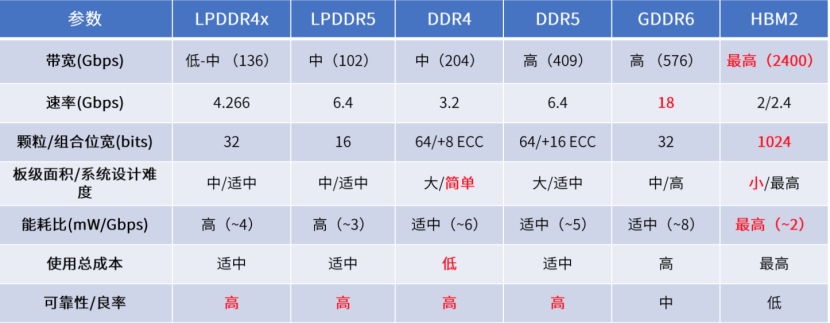
图 HBM与其他几种内存方案的参数对比(图源:芯耀辉)
高带宽是HBM最大的优势,Rambus公司最新发布的HBM3 Ready,已经将数据传输速率提升到8.4Gbps/pin,带宽超过1TB/s,采用标准的16通道设置,可以达到1024位宽接口。与之相对,最新的DDR5也只有64位宽接口,GDDR6只有32位宽接口。
不只是AI芯片,GPU和FPGA等需要高带宽的处理器都非常钟爱HBM。AMD最早携手SK海力士开发了HBM,并在其Fury显卡中首先采用。2017年AMD发布的Vega显卡使用了新一代的HBM2,2019年推出的Radeon VII显卡也搭载了HBM2。
英伟达于2016年在帕斯卡架构的显卡Tesla P100中使用了HBM2,随后的Tesla V100也采用了HBM2。今年,英伟达升级了A100 PCIe GPU加速器,为其配备了80GB HBM2e内存,使带宽达到了惊人的2.0TB/s。
围绕HBM,存储巨头也展开了升级竞赛。在海力士发布了HBM之后,三星在2016年宣布开始批量生产4GB HBM2 DRAM,同时表示将在同一年内生产8GB HBM2 DRAM封装,随后于2017年7月宣布增产8GB HBM2。不甘心被反超的海力士也在2017年下半年开始量产HBM2。
2019年8月,SK海力士宣布成功研发出新一代HBM2E,并于2020年7月宣布开始量产。2020年2月,三星正式宣布推出其16GB HBM2E产品“Flashbolt”,表示将在同年开始量产。
在2021年2月,三星又推出了其首个HBM-PIM(Aquabolt-XL),将AI处理能力整合到HBM2 Aquabolt中。随后,HBM-PIM在赛灵思(Xilinx)Virtex Ultrascale+(Alveo)AI加速器中进行了测试,提升了近2.5倍的系统性能,并降低超过60%的能耗。
至于下一代的HBM3标准,虽然JEDEC尚未正式发布,但是海力士已经发布了他们的产品,公开的最高数据传输速率达到5.2Gbps。而下下一代的HBM4,带宽更是会达到惊人的8TB/s。相比于带宽已经接近极限的DDR,HBM还有无穷的潜力可以发掘。
更大的应用空间

HBM的优点和缺点同样明显。较低的功耗使HBM非常适合功率受限又需要最大带宽的环境,如人工智能计算,或是大型密集计算的数据中心。因为使用额外的硅联通层,通过晶片堆叠技术与处理器连接,这又使HBM又具有多个缺点。
“HBM通过2.5D封装把两个Die在interposer(介质层)上互联到一起,这里面就会出现机械应力、散热等问题,如此复杂的工艺,还会使得良率下降。”白文杰认为这都是HBM相对于传统的DRAM所存在的劣势。
复杂的工艺还带来高昂的成本,这也是HBM很难进入消费级显卡的主要原因。每个HBM堆叠都有上千个连接,因此需要高密度的互连,这远远超过PCB的处理能力。同时,HBM追求最高效能和最佳的电源效率,但成本更高,需要更多的工程时间和技术。
白文杰认为,因为使用了2.5D封装,其较低的良率会增加生产成本。同时,因为要把CPU、DRAM和介质层都封装在一起,整个生产周期会很长,也会增加时间成本。
据了解,HBM其单价是目前DRAM封装的2-3倍,且其尺寸大于LPDDR4芯片。因此,目前它的市场并不大,仅应用于要求超高性能的大型数据中心。但是像所有技术一样,HBM的成本也在随着成熟度增加而不断降低。Rambus IP核产品营销高级总监 Frank Ferro 就表示:“HBM2E实现一个特定的带宽需求可能需要4个DRAM;而HBM3可能只需要2个DRAM,这就带来非常直接的成本下降。”
处理器界的两巨头都将HBM纳入了未来的处理器蓝图中,AMD下一代Zen 4核心的EPYC Genoa处理器将支持HBM,Intel的Sapphire Rapids至强处理器也会有HBM版。这也不禁让人想到一个问题,HBM能否完全取代DDR?
集微咨询总经理韩晓敏认为可能性不大,“HBM主要优势是在高带宽和低功耗领域,并不太符合CPU的使用场景,更多应该还是以配合并行计算的GPU和ASIC芯片为主,取代DDR的可能性不太大。”
白文杰也认为:“DDR协议很难再提高速率了,但是CPU对于速率的需求还不断提升,HBM在某些特定领域是有可能会取代DDR的。”
目前为止,数据中心还是HBM最主要的应用场景,但是新的机会正在慢慢显现。据Frank Ferro判断,随着设备越来越多的边缘化,HBM3也可能被应用在未来的5G设备上,特别是那些对带宽有更高要求的5G设备。
从技术层面来看,限制HBM的环节也正在逐一被化解。据悉,在HBM2的时代,中介层本身的技术是有限制的,即1代和2代的中介层最高只能做到两层,设计的线宽、金属层的厚度都是非常有限的。随着中介层技术的发展,其本身的厚度、金属层和线宽都有了一定的增加,这进一步推动了HBM未来的发展。
业界因此对HBM寄予了深厚的期望。正如Frank Ferro 所言,“HBM的发展很大程度上是由不断上升的带宽需求驱动的,而对带宽的需求几乎没有上限,换句话说,目前来看HBM的发展可能不会遇到障碍。”(校对/艾禾)








