

近年来,以图像压缩感知、恶劣环境(如低光照)图像增强为代表的底层视觉任务因其实用性,受到学术界和工业界的广泛关注。北京大学深圳研究生院信息工程学院张健助理教授课题组近期在图像重建领域取得重要进展,其相关工作发表在IEEE Transactions on Pattern Analysis and Machine Intelligence(简称TPAMI)和International Journal of Computer Vision(简称IJCV)上。TPAMI是模式分析和机器智能领域国际公认的顶级期刊,其最新影响因子为20.8;IJCV是人工智能和计算机视觉领域国际公认的顶级期刊,其最新影响因子为11.6,2022—2023年度发文量198篇。两者均为中国计算机学会(CCF)推荐的A类学术期刊。

文章截图
图像压缩感知(Compressed Sensing,CS)旨在从少量线性观测值中重建原始图像信号,以突破奈奎斯特采样极限、极大地降低信号获取成本,其应用包括但不限于单像素相机、医疗成像(如CT和MRI)以及视频快照和光谱压缩成像等。目前,CS面临两个具有挑战性的问题:(1)如何设计高效的采样矩阵和采样方式,以尽可能多地保留图像信息;(2)如何设计高效的重建算法,以快速、精确地复原图像信号。课题组针对这两个问题,提出一种实用的紧凑深度压缩感知算法,相关成果发表在TPAMI上(论文地址:https://ieeexplore.ieee.org/document/10763443)。

图1 课题组提出的协同采样算子设计方案
针对采样矩阵与采样方式设计问题,课题组研究发现,大多数传统方法对高分辨率图像进行以块为单位的不重叠均匀采样,且传统采样矩阵的自适应能力弱、存储效率低下。如图1所示,课题组提出了一种新的协同采样算子(Collaborative Sampling Operator,COSO),通过深度条件滤波和双分支快速采样,实现了高效的全局采样。
在重建算法设计方面,课题组提出了一个实用、紧致的深度网络(Practical Compact Network,PCNet),通过设计新的协同采样算子和现代化的重建骨干网络,实现了高效的全局采样和可解释的重建。在高分辨率图像上,PCNet展示了显著的性能提升和扩展潜力。
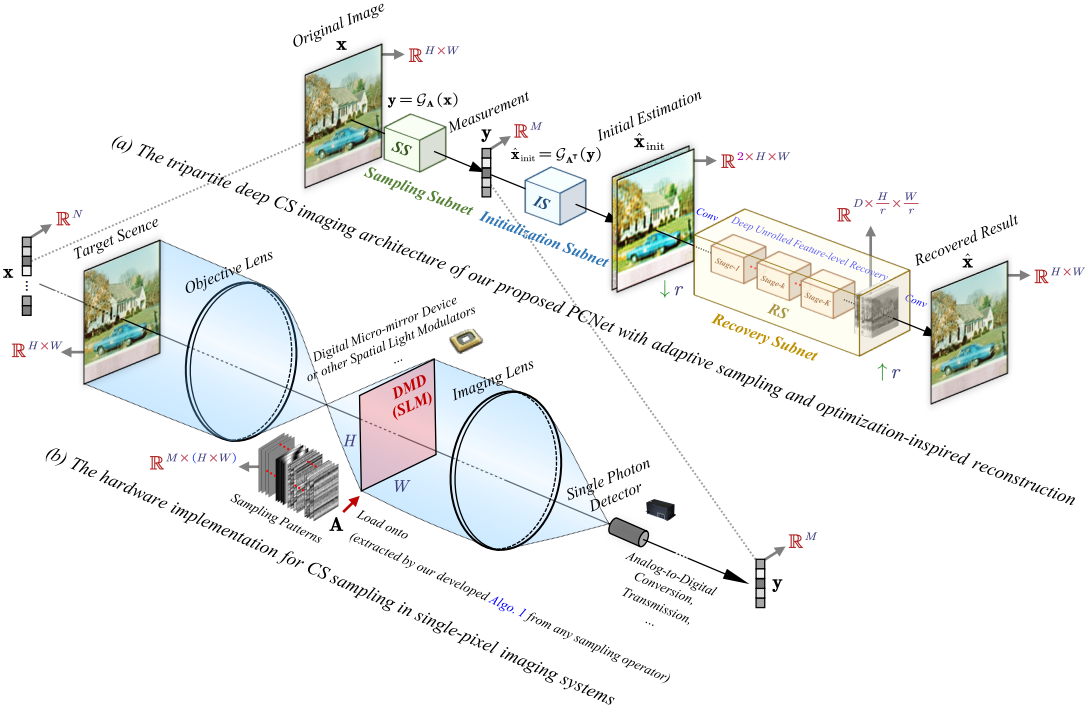
图2 课题组提出的实用、紧致的图像压缩感知神经网络架构图
得益于各模块间良好的兼容性,如图2所示,课题组提出了一个实用、紧致的图像压缩感知神经网络,对所有组件进行端到端的联合训练。该方法在多个图像基准数据集上均取得了领先的性能。

文章截图
低光照增强(Low-light Image Enhancement,LLIE)旨在从受黑夜、阴影等恶劣环境破坏的低光照图像中重建高清图像信号,以求有效识别黑暗中的图像内容,在军事(如夜视仪)、民生(如自动驾驶)等领域存在广泛应用。目前,LLIE面临一个具有挑战性的问题:低光照图像的数据集是有限的,但实际应用时可能面对的低光照退化类型是无限的,在有限的低光照数据集上训练出的算法如何应用于实际场景无限可能的退化是亟需解决的问题。为此,课题组提出一种基于扩散先验的算法,提升增强算法在实际应用中的普适性,相关成果发表在IJCV期刊上(论文地址:https://link.springer.com/article/10.1007/s11263-024-02292-4)。
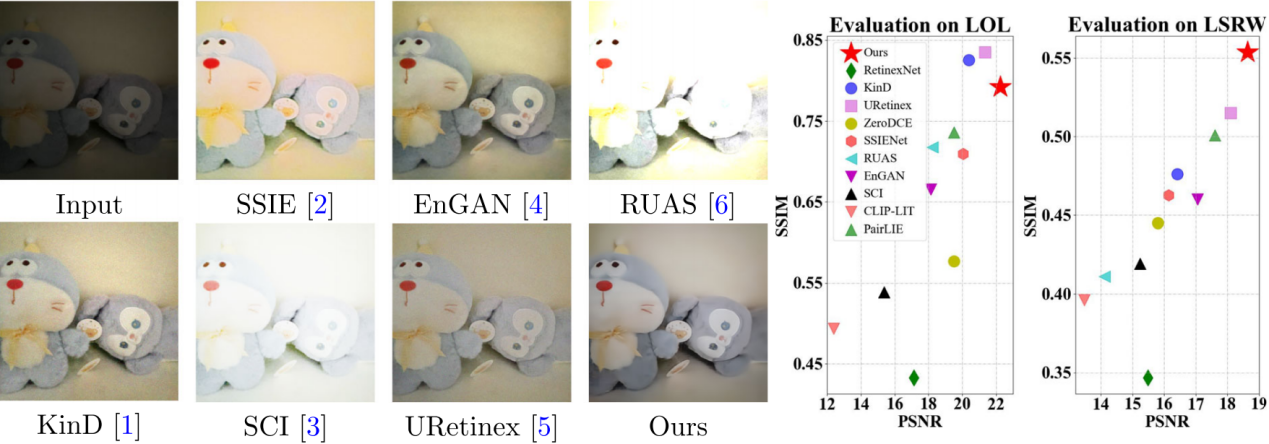
图3:提出的方法与当前最先进算法在真实手机拍摄图像及基准数据集上的结果对比
针对有限低光照图像数据集和实际应用中无限可能的退化之间的冲突问题,课题组研究发现,在大规模自然图像上训练的生成模型(如DDPM)具有非常丰富的自然图像先验,这在一定程度上可弥补有限的低光照图像数据。
如图4所示,一方面,基于DDPM的图像生成模型,课题组提出了一个退化域矫正模块(Degradation Domain Calibration, DDC)。对于真实场景中的低光照图像,先通过DDPM的加噪-去噪采样,在一定程度上将多样的低光照退化统一到一个特定的分布上(即DDPM的生成分布),使后续的低光照增强模型(HWEM)能永远接收到类似的低光照退化输入,降低增强的难度。
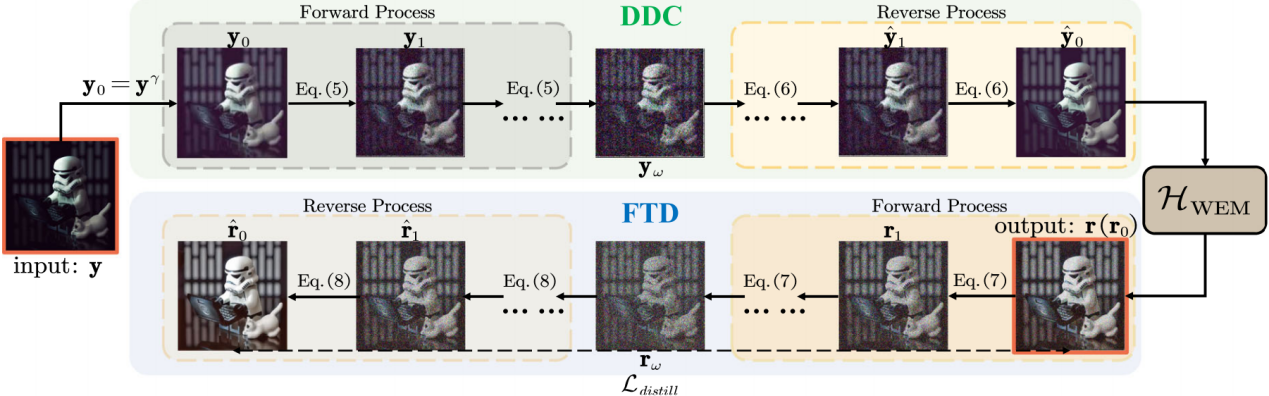
图4:课题组提出的实用、高效的低光照图像增强神经网络
另一方面,如图4所示,对于模型增强后的结果,课题组采用了知识蒸馏的策略,引入细粒度目标域蒸馏操作(Fine-grained Target Domain Distillation, FTD),通过将增强结果再次使用DDPM的加噪-去噪采样进行细粒度优化,进一步提升增强图像的质量。在真实世界捕获的低光照图像上,FTD展现出了显著的性能提升和鲁棒性。
得益于各模块间良好的兼容性,课题组提出了一个实用、高效的低光照图像增强神经网络,可应用于真实场景多变的低光退化。该方法在多个图像基准数据集上均取得了领先的性能。
两项工作均由张健课题组独立完成,论文通讯作者为张健,北京大学信息工程学院为第一作者单位。研究得到国家自然科学基金重点项目以及面上项目支持。
作者简介:
张健是北京大学深圳研究生院信息工程学院助理教授/研究员、博士生导师,视觉信息智能学习实验室(VILLA)负责人。围绕“智能可控图像生成”前沿领域,深入开展高效图像重建、可控图像生成和精准图像编辑3个关键方向研究。近5年以第一作者/通讯作者在Commun Eng、TPAMI、TIP、IJCV、SPM、CVPR、NeurIPS、ICCV等高水平国际期刊和会议上发表论文70余篇,其中CCF A类论文50余篇;谷歌学术引用9800余次,h-index值为49(单篇一作最高引用1200余次);连续5年入选斯坦福全球前2%顶尖科学家榜单;获得北大青年教师教学比赛一等奖、国际期刊/会议最佳论文奖5次、CVPR NTIRE全球挑战赛冠军、华为MindSpore学术奖励基金项目优秀奖等。致力于产学研相结合,成果应用于字节、免展、Stability Al、Hugging Face等国内外知名公司产品中。主页:https://jianzhang.tech/cn。





评论
文明上网理性发言,请遵守新闻评论服务协议
登录参与评论
0/1000