英伟达在GTC 2024大会上以革命性架构引爆行业的NVL72机柜,仅一年时间便从技术标杆蜕变为产业生态标杆。GTC 2025大会上,业界不同设计的NVL72量产级样机亮相,标志着全互联GPU架构正式进入商业化落地阶段。以NVL72为代表的全互联GPU架构,在算力密度、散热效率、节能降耗、可扩展性等领域优势明显,是面向百亿亿级 (Exascale) AI 超级计算应用的最佳方向选择。

图片来源:NIDIA GTC 2025 Online Press Kits
华勤技术ETH-X架构AI RACK 本土化高性能计算的创新答案
全互联GPU产品架构设计十分复杂,涉及GPU、Switch、Cable Tray、Power Shelf、Busbar供电、液冷等一列复杂内容,尤其是GPU间的互联能力,对系统厂商的综合能力提出了前所未有的要求。
华勤技术作为国内为数不多的同时具备服务器和交换机技术能力的厂商,在ODCC(开放数据中心委员会)网络工作组的指导下,牵头设计符合ETH-X超节点架构的整机柜服务器,成功打造了一款集高密度、绿色、智能于一体的三总线架构液冷整机柜系统,并在2024年9月正式发布《ETH-X 超节点 AI 整机柜设计规范》。

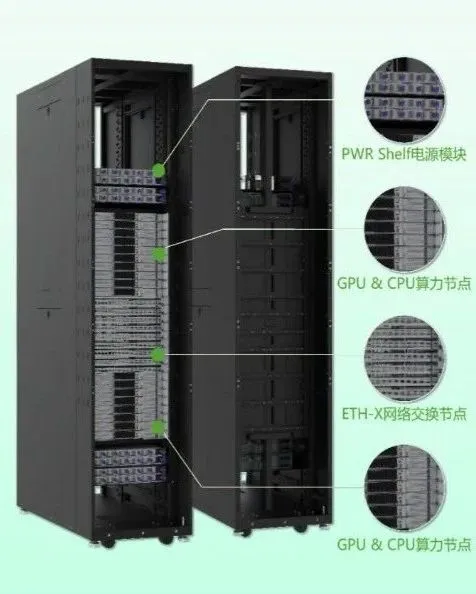
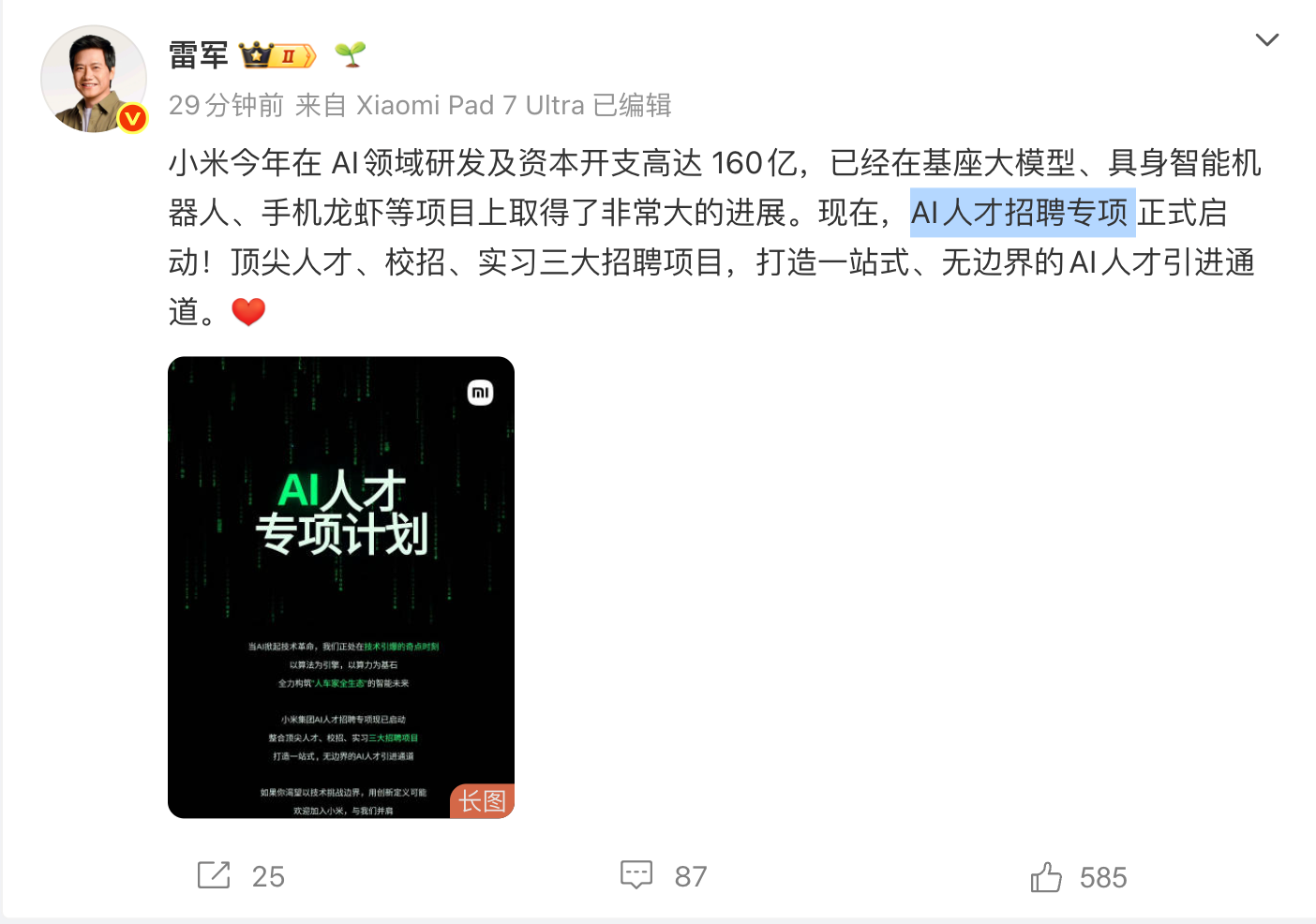
基于ETH-X架构开发的华勤技术AI RACK整体系统,关键设计参数如下:
1)RACK:52U, 兼容标准21寸机柜;
2)节点:16个计算节点,8~12个交换节点(视不同厂家GPU而定);
3)供电:4个Power Shelf,Busbar供电,整机支持120KW;
4)散热:液冷为主,风冷为辅;支持漏液检测;
5)计算节点:1个CPU搭配4GPU,支持主流国产GPU新一代芯片;
6)交换节点:单个或多个Switch芯片;
7)系统设计支持多家GPU/Switch/NIC芯片设计。
在核心的互联方面,华勤技术AI RACK针对不同国产GPU特性,设计两款通用型计算节点,支持多种系统互联方式。华勤技术充分发挥在网络交换方面的技术积累优势,交换节点采用5nm交换芯片,可支持51.2T超算级带宽,专为万卡AI训练集群设计,可实现低时延高带宽AI智算网络。对外支持32个800G OSFP端口,向下兼容400G/200G/100G,同时支持铜缆DAC、AEC和光模块互联,可支持跨柜Scale up 模型搭建。背板Cable Tray互联设计,差分对数量最大达到6144对,通过搭配不同的Cable tray,即可实现单柜最高64pcs GPU的互联。
面向国产算力基建的全新选择
在全球AI竞速时代,华勤技术AI RACK采用国内ETH-X最新架构设计,通过本土化创新开辟了一条更适配国产GPU的高性能计算路径。在算力自主化与AI应用爆发的大趋势下,华勤技术ETH-X架构AI RACK以开放生态、灵活架构和成本优势,为采用国产GPU构建下一代智算中心提供了全新选择。