
近日,第七十三届国际固态电路大会ISSCC 2026(被誉为“芯片设计国际奥林匹克”)在美国旧金山举行,该会议是集成电路领域最具影响力的国际学术会议之一。本届大会上,北京大学共有6篇高水平论文入选(按第一单位统计)。北京大学集成电路学院部分师生赴美参会,集中展示了在多个方向的最新研究进展,并与国际同行开展了深入的学术交流与合作讨论。
会议期间,唐希源研究员、汝嘉耘研究员担任会议Data Converters、RF Subcommittee技术程序委员会(TPC)成员,汝嘉耘研究员担任ISSCC 2025 Forum 5 Organizer组织了 “Analog for AI and AI for Analog: What the Analog/RF People Can Do and Leverage in the AI Era”的专题研讨论坛。
会上,2022级博士生吴子涵荣获the Kenneth C. (KC) Smith Award,2022级博士生王宗楠、高继航荣获SSCS国际固态电路协会博士成就奖(SSCS Predoctoral Achievement Award)。吴子涵博士由北京大学集成电路学院王源教授和军事医学科学院伯晓晨研究员两位老师联合指导,他围绕“以电路技术重构组合优化计算范式”展开探索与研究,已累计发表核心期刊与会议论文15篇;王宗楠由唐希源研究员指导,研究方向为模拟与数模混合信号集成电路设计,已累计发表核心期刊与会议论文12篇;高继航由沈林晓研究员指导,他的主要研究方向集中于高能效的模数转换器和模拟前端电路设计,已累计发表核心期刊与会议论文20篇,此外,他还以第一作者身份获得了2023年ISSCC的最佳技术论文奖,也是中国大陆及港澳地区自ISSCC创办以来首次获得该荣誉。




此次入选的6篇论文涵盖模拟与混合信号电路、人工智能、硬件加速、通信等研究领域。相关工作介绍如下:
工作1:模式可重构K-SAT求解器
K-SAT方程是现代金融分析与电子设计自动化领域的核心问题。当前, ASIC加速器在求解K-SAT方程时面临两大核心瓶颈:其一,现有求解器难以适配问题实例的规模与结构波动,当计算阵列与公式规模错配时,系统硬件利用率会大幅下降;其二,其对现实实例的结构化特征利用不足,未能充分挖掘公式内部存在的局部强关联社区结构。
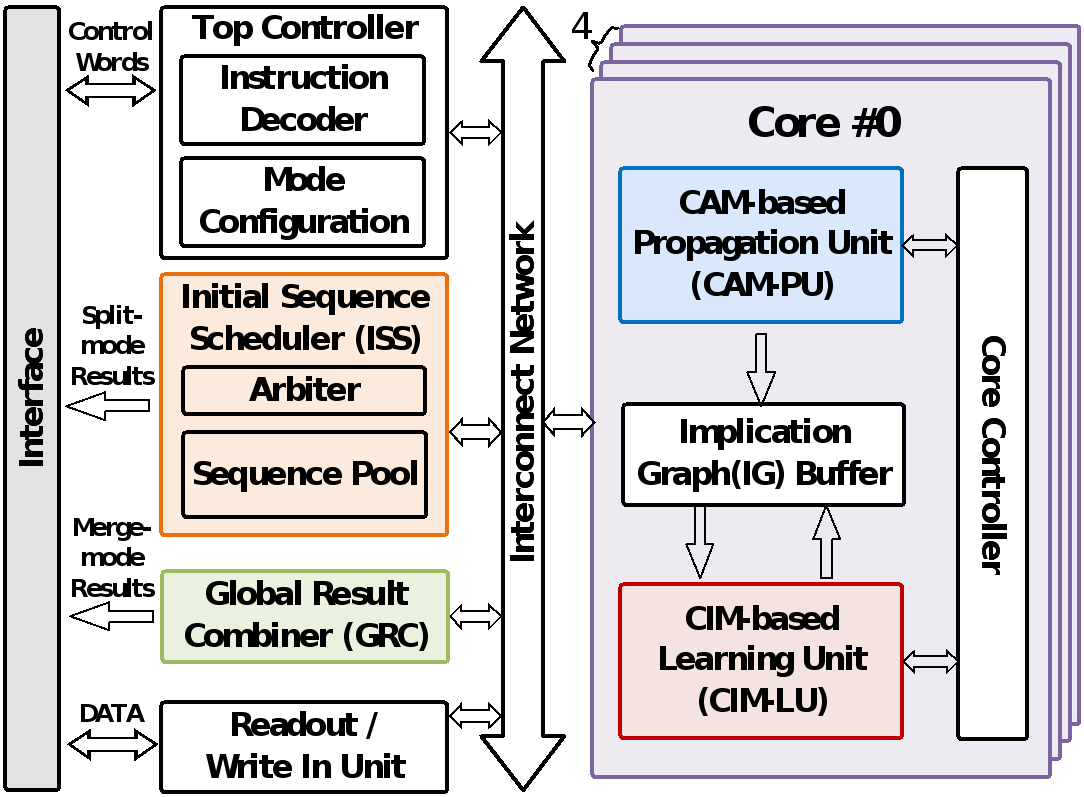
针对上述挑战,北京大学团队提出一种模式可重构CAM-CIM混合异构的K-SAT求解加速器芯片。该架构具备两大核心特征:一是采用CAM-CIM混合异构设计,实现冲突感知(conflict-aware)的推理流水,在子句传播与学习的吞吐之间达成高效平衡,进而达成公式内生蕴含图的精准分析与学习,以确保推理性能的最优化;二是针对不同问题长度波动引发的能效下滑,提出多核异构求解架构,可根据输入问题长度,自适应实现数据并行与线程并行之间的切换。该工作于28-nm工艺下完成物理实现,实验结果表明,该相关工作相较于此前性能最优的完备性求解器,求解速度提升4.28-5.07倍,能耗降低1.40-1.66倍。
该成果以《A 28-nm Mode-Reconfigurable CAM-CIM Hybrid Complete 3-SAT Solver Supporting Conflict-Driven Clause Learning with 100% Solvability》为题,发表于数字加速器和电路技术(Digital Processing and Circuit Techniques)分会场,博士生吴子涵为第一作者,通讯作者为唐希源、王源。

工作2:自动语音识别加速器
随着人工智能辅助设备的普及,实时多人声自动语音识别(ASR)引起了广泛关注。然而,传统的ASR 模型在处理实时流式、多说话人对话时面临严峻挑战,频繁的说话人切换会导致推理延迟增加和识别准确率下降。现有的 ASR 加速器芯片大多仅针对单说话人场景,尚未充分考虑现实生活中多说话人语音识别的独特部署需求。
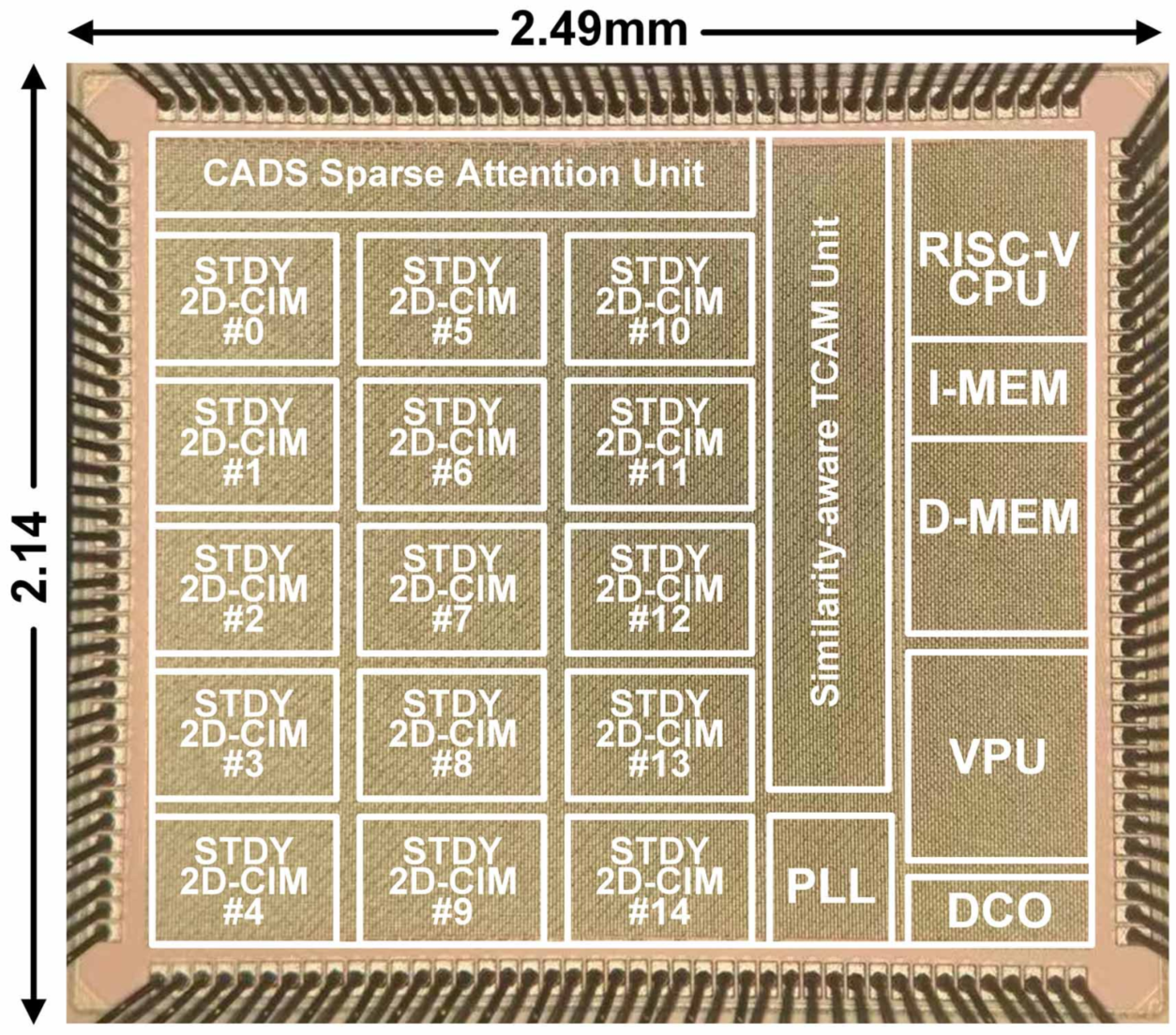
针对上述问题,北京大学团队提出了一种流式多人声语音识别的加速器芯片。上下文感知冗余跳过(CARS)单元基于在线稀疏块预测机制,通过相似性跳过单元和空白跳过单元,动态跳过重复或无信息的语音块。针对模型部署的存储和计算需求,二维可写存内计算宏单元(2D-Writable CIM),通过静态页面存储权重来降低快速预识别阶段的高频访存功耗,动态页面支持原生的存内矩阵转置和稀疏矩阵计算。为了快速识别多说话人的切换,设计了支持汉明距离近似匹配的TCAM,用于快速搜索相似的说话人身份信息。与之前的 ASR 加速器相比,该芯片实现了 2.39-3.20 倍的速度提升和 1.91-3.84 倍的功耗降低。
该工作以《A 22nm 1.87ms/Frame Streaming Multi-Speaker ASR Accelerator Leveraging Contextual-Aware Redundancy Skipping with 2D-Writable Microscaling Compute-in-Memory and Similarity-Aware TCAM Design》为题发表。博士生任文捷,李明轩为共同第一作者,通讯作者为贾天宇、叶乐。
工作3:面向视觉自回归模型的算力可扩展多精度PE-LUT加速器芯片
视觉自回归模型作为视觉内容生成领域的新型范式,相较于传统扩散模型和自回归模型,在生成效率与图像质量方面展现出显著优势。其推理过程采用“由粗到细”的生成策略:从低分辨率逐步提升至高分辨率。然而,动态增长的分辨率带来不断变化的计算需求,导致硬件利用率下降。同时,激活矩阵的数据分布差异明显,固定精度量化引发图像质量退化。KV Cache机制使注意力层存储开销随分辨率提升而快速增长。
针对上述挑战,北京大学团队提出了面向视觉自回归模型的算力可扩展多精度PE-LUT加速器芯片VARSA。该芯片采用混合PE-LUT架构,通过配置LUT的工作模式实现算力的动态扩展,并结合地址掩码与时钟门控降低功耗。多精度量化策略将不同精度计算块动态映射至各PE-LUT核并行执行,并实现INT4/8/12高效支持。同时利用注意力图的网格间相似性进行压缩,减少KV Cache访问与计算开销。基于上述关键技术,基于22nm工艺的VARSA芯片在混合精度配置下达到18.38 TOPS/W的实际硬件能效。在512×512图像生成任务中,实现单张图像503 mJ的推理能耗与1.92 s的推理时延。与现有基于扩散模型的加速器相比,VARSA取得了2.7–8.9倍能效提升和1.2–3.8倍性能提升,达到国际领先水平。
该工作以《VARSA: A Visual Autoregressive Generation Accelerator Using Performance-Scalable Multi-Precision PE-LUT and Grid-Similarity Attention Compression》为题,发表于AI加速器芯片(Session 31 AI Accelerators)分会场,博士生周嘉琪为第一作者,通讯作者为贾天宇。

工作4:基于双残差量化方法的高精度低延迟模数转换器芯片
随着边缘端应用的发展,信号链系统对模数转换器提出了高能效、低延迟和高精度兼具的要求。多级模数转换器通过放大前级量化误差并传递至后级继续量化,在提升速度和能效的同时,其性能却高度依赖级间放大器的增益精度。传统闭环放大器功耗高、设计复杂,而低功耗开环放大器又难以保证精确增益。双残差架构通过传递正负两路残差并量化其比例关系,在理论上降低了对增益精度的依赖,但受限于复杂插值电路,其分辨率通常有限,难以满足高精度信号链需求。
针对这一瓶颈,北京大学唐希源研究员团队提出了一种基于ΔΣ调制的双残差量化方法。该方法将前级量化器产生的两路互补残差经级间放大后送入后级量化器,后级不再依赖插值器计算残差比例,而是直接利用双残差信息对前级量化误差进行高分辨率ΔΣ转换。该方法在保持对级间增益误差不敏感特性的同时,省去了复杂且分辨率受限的插值电路。结合指数型量化机制,可在较少转换次数下获得高分辨率结果,缩短转换时间并提升整体效率。基于该技术,课题组在22nm CMOS工艺下实现的增量型模数转换器芯片取得了85.1dB的信噪失真比和8MS/s的转换速度,在同类双残差架构模数转换器中精度最高。该芯片核心功耗仅618.1μW,对应的能效优值(FoMs)达到183.2dB,在转换速度高于5MS/s的模数转换器芯片中处于领先水平。
该工作以《An 85.1dB-SNDR 8MS/s Incremental Pipeline ADC with Dual-Residue-Assisted Exponential Quantization》为题,发表于今年ISSCC,博士生王宗楠为第一作者,文章的通讯作者为唐希源。
工作5: TDC辅助的流水线-逐次逼近型模数转换器
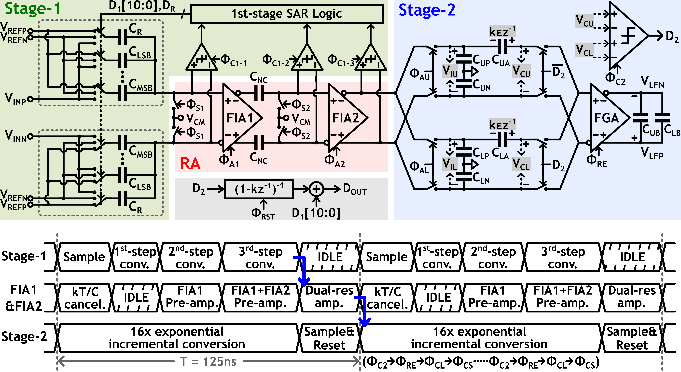
随着5G/6G通信及高速有线系统的快速发展,对于兼具高分辨率(≥14b)和数百MS/s采样率的模数转换器(ADC)需求日益迫切。采用电压-时间转换器(VTC)和时间-数字转换器(TDC)的时间域(TD)量化技术虽能提升转换速度,但传统VTC由于线性输入范围受限,且增益和失调易受工艺、电压和温度(PVT)波动影响,限制了其在高动态范围场景下的应用。
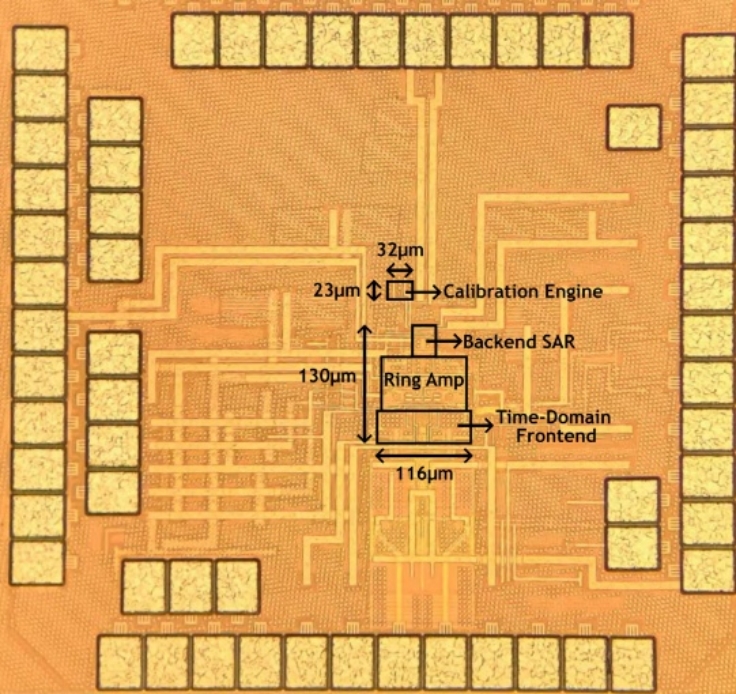
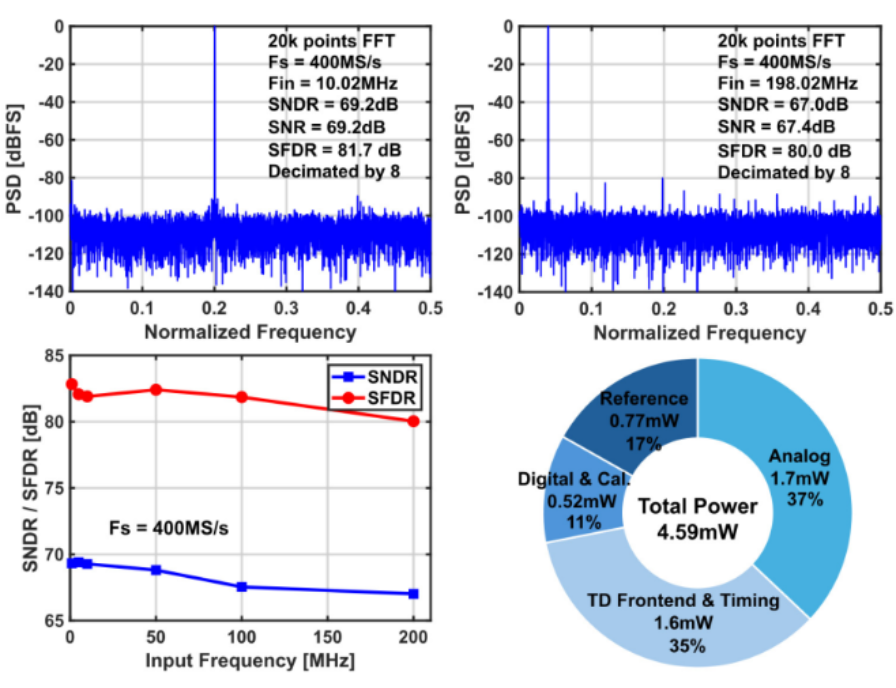
针对上述挑战,北京大学团队提出了一款14位 400MS/s 的TDC辅助流水线-逐次逼近型ADC,创新性地引入了具有轨到轨输入特性的线性化VTC及后台时间域误差校准引擎。该VTC通过引入由源极跟随器驱动的电平移位并联输入分支,在1.8Vpp轨到轨输入下仍能保持线性的转移特性,有效扩展了TDC的动态范围。同时,研究团队开发了一套基于数字输出统计特性的后台校准算法,在最小化模拟硬件开销的前提下,实现了对VTC增益、失调以及相位插值器(PI)失调的精确修正,显著提升了系统的鲁棒性。基于28nm CMOS工艺,该ADC在400MS/s采样率和1.8Vpp差分输入摆幅下实现了69.2dB(低频输入)和67dB (奈奎斯特频率输入)的SNDR,总功耗仅为4.59mW。其能量效率(FoMw)达到6.3fJ/conv.-step,在同类单通道高速高分辨率ADC中展现出较强的国际竞争力。
该成果以《A 14b 400MS/s TDC-Assisted Pipelined-SAR ADC with Rail-to-Rail Input VTC and Background Time-Domain Error Calibration》为题,发表于流水线与超高速数据转换器(Session 11: Pipeline and Ultra-High-Speed Data Converters)分会场。博士生王璟鹏为第一作者,通讯作者为唐希源。
工作6:配备动态均衡器的单端全双工收发机
人工智能的高速发展对芯粒间互联接口的带宽密度与能量效率提出了更高要求,更高的单线速率带来了更大的信道插损,高密度集成下串扰严重等问题也对芯粒间互联收发机提出了新的挑战。
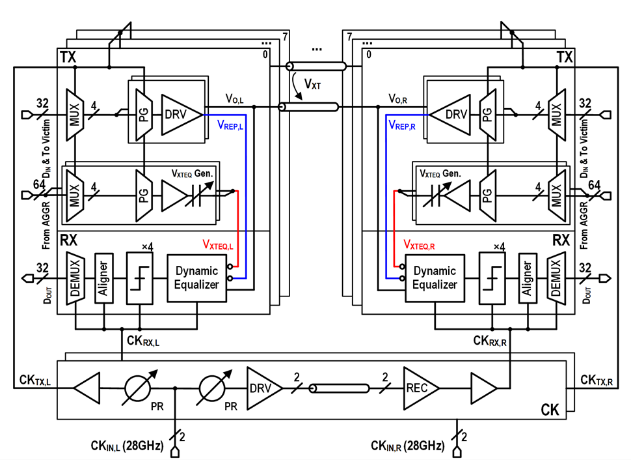
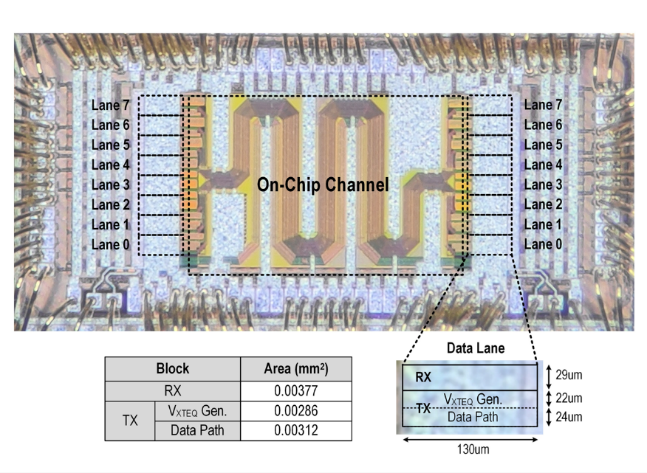
针对以上问题,北京大学团队研制了一款单通道112Gb/s的全双工收发机芯片,使用动态插损均衡器技术,在时钟控制的放大级中增加高通信号路径以补偿信号高频衰减,该方案消除了长通电流,显著降低系统功耗;提出了低功耗近端串扰消除方案,利用高频无源滤波电路拟合信道近端串扰,并通过动态判决器的判决过程实现信号相减,以更低功耗有效抑制近端串扰;同时研究了高速时钟分频技术,采用延迟匹配的真单相时钟D触发器构建分频器进行分频,确保分频后时钟频率与占空比的稳定性。上述关键技术协同优化,显著提升了芯粒互连的传输性能与能效比。团队采用28nm工艺成功研制并流片验证了八通道全双工收发机,收发机误码率低于1e-14,能量效率为1.01 pJ/bit,达到国际领先水平。
该工作以“A 112 Gb/s/wire Single-Ended Simultaneous Bi-Directional Transceiver with Dynamic Equalizer for Die-to-Die Interface in 28nm CMOS”为题发表,博士生黄之闻、王知非为共同第一作者,通讯作者为盖伟新。
会议期间,北京大学集成电路学院联合北京大学北加州校友会共同举办年度校友交流联谊活动,邀请了学术界、产业界及相关领域的北大校友与业界友人相聚旧金山,为进一步深化母校与校友的联结,共话前沿技术。学院教师代表唐希源向广大校友转达了学院的亲切问候,并向校友介绍了学院最新发展动态与建设成果。自由交流环节中,与会师生与校友围绕学术前沿、产业实践等话题展开热烈交流。










