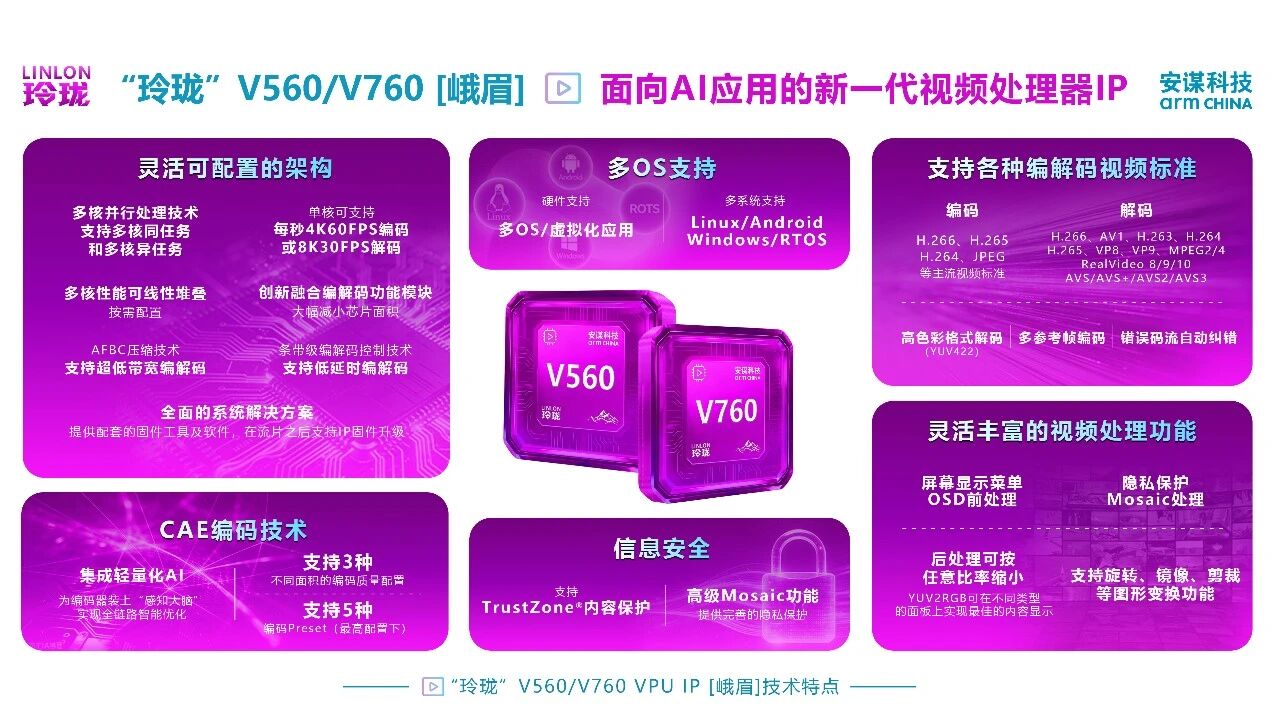
安谋科技Tech Talk AI技术开放麦第二期,NPU高级产品经理Benjamin Ye分享了“周易”X3 NPU IP R2版本升级亮点,详解该版本在算力、算力密度方面的提升,以及“周易”X3系列NPU在智能座舱、AI推理加速芯片及新兴市场等多领域的落地案例。
周易”X3 R2版本升级
最高算力翻倍、算力密度提升超70%
当前,AI大模型加速从云端向边端侧迁移,对边端侧NPU的算力和效率提出了更高要求。对此,安谋科技“周易”X3 NPU IP持续升级,Benjamin Ye表示,R2版本重点聚焦W4A8、W4A16两种主流大模型量化精度,进行深度的性能加速与优化,实现算力与效率的双重跃升。
最高算力翻倍,模型部署更流畅。相较于R1,“周易”X3 R2在W4A8、W4A16格式下的算力最高实现翻倍提升,单Cluster算力从8-80 TFLOPS跃升至8-160 TFLOPS,且支持灵活配置。边端侧设备能以更高吞吐率运行更大参数量的模型,在保证量化推理精度的同时显著缩短响应延迟,为AI的规模化部署提供强劲算力底座;
算力密度提升超70%,成本优势更显著。“周易”X3 R2相比R1的算力密度提升超70%1——即在相同芯片面积下可提供更强有效算力,或在同等算力需求下显著缩减芯片面积。这帮助SoC厂商在满足算力需求的同时,有效控制硬件成本,释放芯片空间用于其他功能模块的设计,从而获得更大的产品定义空间与市场竞争力。

多元场景成功落地
满足客户边端侧AI需求
据Benjamin Ye介绍,“周易”X3 R1/R2系列NPU IP凭借其在架构设计、软硬深度协同、全生命周期支持等方面的核心优势,目前已在多领域应用落地,满足客户多样化需求。
智能座舱:全面支撑座舱个性化智能助手、多模态舱内外智能感知,以及驾驶员监测(DMS)、乘客监测(OMS)、自动泊车等核心功能,为智能汽车打造低延迟、高流畅的沉浸式驾乘体验;
AI推理加速芯片:广泛赋能本地及轻量服务器端Agent应用,支持图文/视频内容审核、智能检测与标注等多模态理解任务,并应用于边缘AI工作站与边缘服务器,满足企业级高吞吐推理需求;
新兴市场领域:同时兼顾传统视觉任务与小语言模型应用需求,可灵活适配智能家庭中枢、个人智能助手、便携式工作站等多种产品形态,助力终端设备智能化升级。

软硬深度协同
进一步释放硬件算力潜能
据Benjamin Ye介绍,“周易”X3 R2延续了R1通用、灵活、高效且软硬协同的核心优势,采用专为大模型而设计的DSP+DSA架构,兼顾CNN与Transformer模型,能够进一步释放硬件算力潜力,与AI技术的快速演进保持同频。
硬件设计上,“周易”X3 R2具备完整的Tensor计算能力,单Core带宽高达256GB/s,配合WDC权重无损解压引擎,计算效率和密度大幅提升。集成AI专属硬件引擎AIFF,配合高频计算硬化加速、自定义运算和硬化任务调度器等单元,可实现超低CPU负载和多优先级任务的灵活调度。
软件层面,“周易”X3 R2配套了完善易用的Compass AI软件平台。该平台提供统一的端到端AIPULLM工具链,可实现“一键部署,开箱即用”,同时原生支持Hugging Face、主流AI框架与OS,并对LLM/VLM/VLA等大模型推理进行深度优化,显著降低模型部署门槛与成本。此外,该平台具备高度的灵活性与开放性,为客户提供了充分的定制化空间,助力实现产品的差异化设计。
面向未来,在安谋科技“All in AI”产品战略指引下,“周易”NPU将沿着计算架构、数据格式、通用计算、开放生态、软件界面与计算扩展等方向持续升级,以创新技术为锚点、开放生态为纽带,持续为边端侧AI产业注入核芯动能,与合作伙伴共赴智能计算新时代。